I have a following question. I have this dataframe:
import pandas as pd
import matplotlib.pyplot as plt
data = {'date': ["2021-05-03", "2021-05-04", "2021-05-11", "2021-05-19", "2021-05-19"], 'id_customer': ["5", "7", "8", "5", "3"], 'value_dummy': [1, 0, 1, 1,0]}
df = pd.DataFrame.from_dict(data)
I know how to plot a histogram of all variables in value_dummy column:
df['value_dummy'].value_counts().plot(kind='bar')
plt.show()
But I would like to have one graph with three histograms where each histogram will correspond to one week. In this case I will have "week 1" (for observations from "2021-05-03" and "2021-05-04"), "week 2" (for observation from "2021-05-11") and "week 3" (for all observations from "2021-05-19") on horizontal axis. And corresponding histograms for each week. How can I do that, please?
Desired output is this:
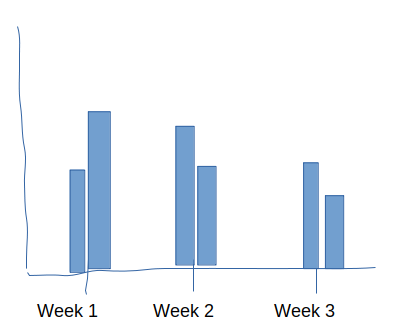
CodePudding user response:
To group by weeks and account for non-contiguous dates and plot subplots of histograms:
import pandas as pd
import matplotlib.pyplot as plt
week1 = pd.date_range(start="2021-05-03", end="2021-05-10")
week2 = pd.date_range(start="2021-05-11", end="2021-05-18")
week3 = pd.date_range(start="2021-05-19", end="2021-05-26")
weeks = [week1, week2, week3]
data = {
'date':
["2021-05-03", "2021-05-04", "2021-05-11", "2021-05-19", "2021-05-19"],
'id_customer': ["5", "7", "8", "5", "3"],
'value_dummy': [1, 0, 1, 1, 0]
}
df = pd.DataFrame.from_dict(data)
df['date'] = pd.to_datetime(df.date)
df.set_index('date', inplace=True)
fig, axes = plt.subplots(ncols=len(weeks), figsize=(15, 3))
axes = list(axes)
for w in weeks:
fig.add_subplot(df.loc[df.index.intersection(w)].plot(kind="hist",
ax=axes.pop()))
plt.tight_layout()
plt.show()

Of course no use really in visualizing histograms with so little data... I assume you have a larger dataset!
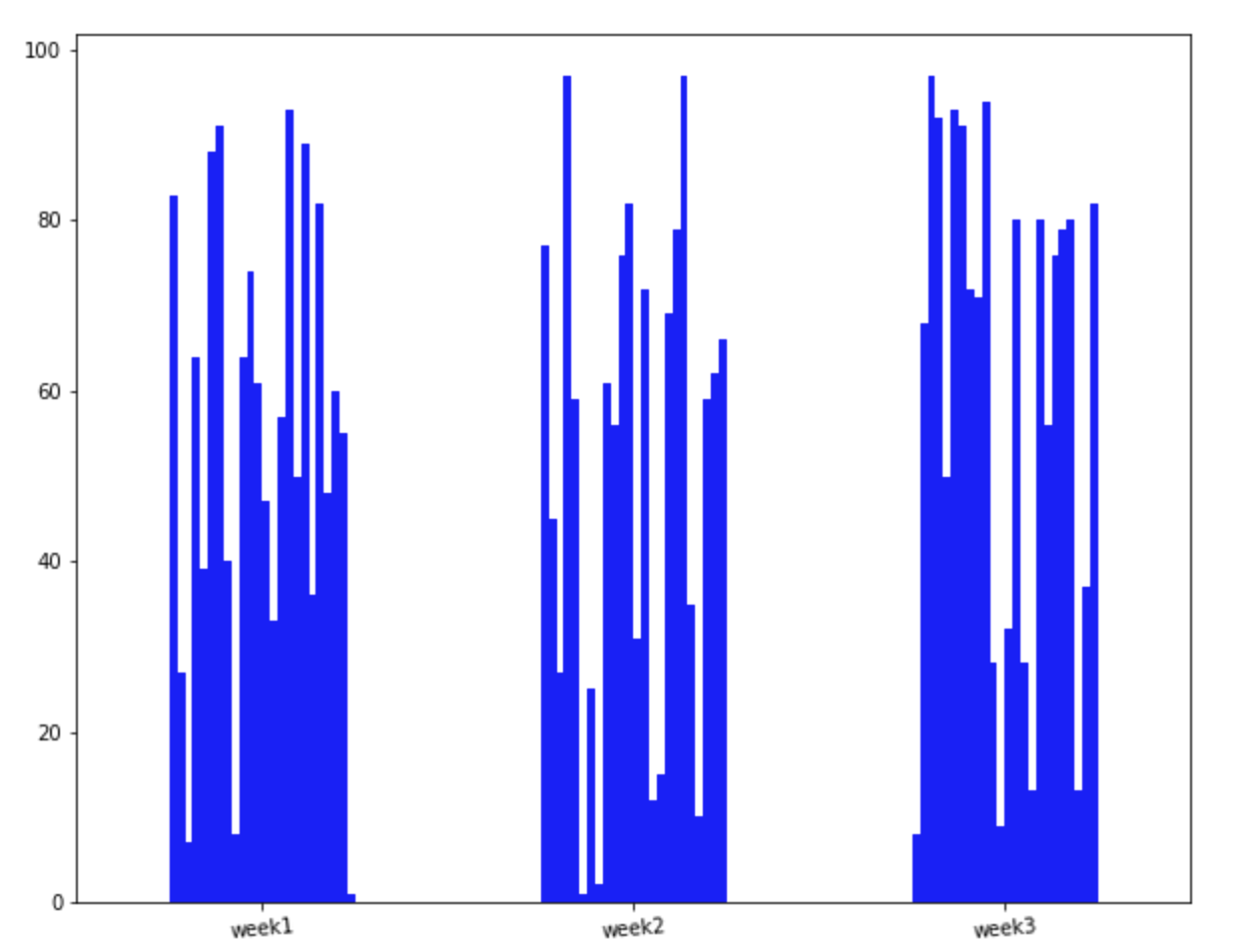
To groupby custom weeks and plot a single bar graph
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
week1 = pd.date_range(start="2021-05-03", end="2021-05-10") # , freq="W")
week2 = pd.date_range(start="2021-05-11", end="2021-05-18") # , freq="W")
week3 = pd.date_range(start="2021-05-19", end="2021-05-26") # , freq="W")
weeks = week1.union(week2).union(week3)
df = pd.DataFrame(
np.random.randint(100, size=72),
columns=["value"],
index=pd.MultiIndex.from_product([weeks, ["week1", "week2", "week3"]]),
)
df.unstack().droplevel(0, axis=1).T.plot(kind="bar", legend=False, rot=5, figsize=(10,8), color='b')
CodePudding user response:
This how you have to do :
import pandas as pd
import matplotlib.pyplot as plt
data = {'date': ["2021-05-03", "2021-05-04", "2021-05-11", "2021-05-19", "2021-05-19"], 'id_customer': ["5", "7", "8", "5", "3"], 'value_dummy': [1, 0, 1, 1,0]}
df = pd.DataFrame.from_dict(data)
fig, axes = plt.subplots(ncols=len(df.columns), figsize=(10,5))
for col, ax in zip(df, axes):
df['formatted_date'] = pd.to_datetime(df['date'])
df['week_of_year'] = df.formatted_date.apply(lambda x: x.weekofyear)
df['week_of_year'].value_counts().sort_index().plot.bar(ax=ax, title=col)
plt.tight_layout()
plt.show()