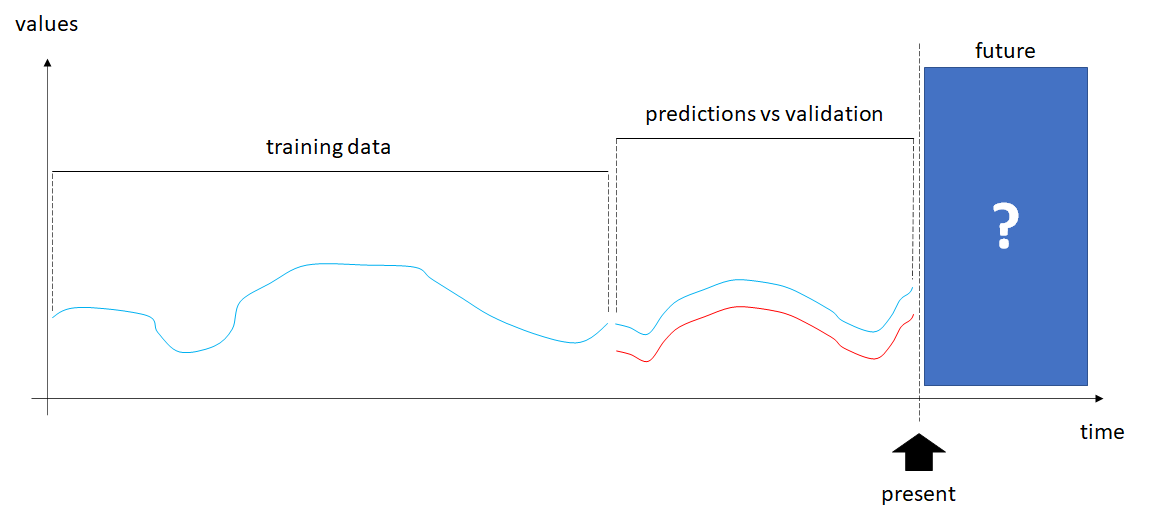
When dealing with time series forecasting, I've seen most people follow these steps when using an LSTM model:
- Obtain, clean, and pre-process data
- Take out validation dataset for future comparison with model predictions
- Initialise and train LSTM model
- Use a copy of validation dataset to be pre-processed exactly like the training data
- Use trained model to make predictions on the transformed validation data
- Evaluate results: predictions vs validation
However, if the model is accurate, how do you make predictions that go beyond the end of the validation period?
The following only accepts data that have been transformed in the same way as the training data, but for predictions that go beyond the validation period, you don't have any input data to feed to the model. So, how do people do this?
# Predictions vs validation
predictions = model.predict(transformed_validation)
# Future predictions
future_predictions = model.predict(?)
CodePudding user response:
To predict the ith value, your LSTM model need last N values. So if you want to forecast, you should use each prediction to predict the next one.
In other terms you have to loop over something like
prediction = model.predict(X[-N:])
X.append(prediction)
As you can guess, you add your output in your input that's why your predictions can diverge and amplify uncertainty.
Other model are more stable to predict far future.
CodePudding user response:
You have to break your data into training and testing and then fit your mode. Finally, you make a prediction like this.
future_predictions = model.predict(X_test)
Check out the link below for all details.
https://towardsdatascience.com/lstm-time-series-forecasting-predicting-stock-prices-using-an-lstm-model-6223e9644a2f