Here I have tried to add all numbers between 0 and 1e9 using 3 methods:
- Normal Sequential execution(Single Thread)
- Creating multiple process to add a smaller part(using fork) and adding all smaller parts at end, and
- Creating multiple thread to do same as of 2nd method.
As far as I know that thread creations are fast and hence called light-weight process.
But on executing my code, I found the 2nd method (multiple process) was the fastest, followed by 1st method (Sequential) and then 3rd (multi-threading). But I am unable to figure out why is that happening so (May be some mistakes in execution time calculation, or make be something is different in my system, etc).
Here is my code C code:
#include "stdlib.h"
#include "stdio.h"
#include "unistd.h"
#include "string.h"
#include "time.h"
#include "sys/wait.h"
#include "sys/types.h"
#include "sys/sysinfo.h"
#include "pthread.h"
#define min(a,b) (a < b ? a : b)
int n = 1e9 24; // 2, 4, 8 multiple
double show(clock_t s, clock_t e, int n, char *label){
double t = (double)(e - s)/(double)(CLOCKS_PER_SEC);
printf("=== N %d\tT %.6lf\tlabel\t%s === \n", n, t, label);
return t;
}
void init(){
clock_t start, end;
long long int sum = 0;
start = clock();
for(int i=0; i<n; i ) sum = i;
end = clock();
show(start, end, n, "Single thread");
printf("Sum %lld\n", sum);
}
long long eachPart(int a, int b){
long long s = 0;
for(int i=a; i<b; i ) s = i;
return s;
}
// multiple process with fork
void splitter(int a, int b, int fd[2], int n_cores){ // a,b are useless (ignore)
clock_t s, e;
s = clock();
int ncores = n_cores;
// printf("cores %d\n", ncores);
int each = (b - a)/ncores, cc = 0;
pid_t ff;
for(int i=0; i<n; i =each){
if((ff = fork()) == 0 ){
long long sum = eachPart(i, min(i each, n) );
// printf("%d->%d, %d - %d - %lld\n", i, i each, cc, getpid(), sum);
write(fd[1], &sum, sizeof(sum));
exit(0);
}
else if(ff > 0) cc ;
else printf("fork error\n");
}
int j = 0;
while(j < cc){
int res = wait(NULL);
// printf("finished r: %d\n", res);
j ;
}
long long ans = 0, temp;
while(cc--){
read(fd[0], &temp, sizeof(temp));
// printf("c : %d, t : %lld\n", cc, temp);
ans = temp;
}
e = clock();
show(s, e, n, "Multiple processess used");
printf("Sum %lld\tcores used %d\n", ans, ncores);
}
// multi threading used
typedef struct SS{
int s, e;
} SS;
int tfd[2];
void* subTask(void *p){
SS *t = (SS*)p;
long long *s = (long long*)malloc(sizeof(long long));
*s = 0;
for(int i=t->s; i<t->e; i ){
(*s) = (*s) i;
}
write(tfd[1], s, sizeof(long long));
return NULL;
}
void threadSplitter(int a, int b, int n_thread){ // a,b are useless (ignore)
clock_t sc, e;
sc = clock();
int nthread = n_thread;
pthread_t thread[nthread];
int each = n/nthread, cc = 0, s = 0;
for(int i=0; i<nthread; i ){
if(i == nthread - 1){
SS *t = (SS*)malloc(sizeof(SS));
t->s = s, t->e = n; // start and end point
if((pthread_create(&thread[i], NULL, &subTask, t))) printf("Thread failed\n");
s = n; // update start point
}
else {
SS *t = (SS*)malloc(sizeof(SS));
t->s = s, t->e = s each; // start and end point
if((pthread_create(&thread[i], NULL, &subTask, t))) printf("Thread failed\n");
s = each; // update start point
}
}
long long ans = 0, tmp;
// for(int i=0; i<nthread; i ){
// void *dd;
// pthread_join(thread[i], &dd);
// // printf("i : %d s : %lld\n", i, *((long long*)dd));
// ans = *((long long*)dd);
// }
int cnt = 0;
while(cnt < nthread){
read(tfd[0], &tmp, sizeof(tmp));
ans = tmp;
cnt = 1;
}
e = clock();
show(sc, e, n, "Multi Threading");
printf("Sum %lld\tThreads used %d\n", ans, nthread);
}
int main(int argc, char* argv[]){
init();
printf("argc : %d\n", argc);
// ncore - processes
int fds[2];
pipe(fds);
int cores = get_nprocs();
splitter(0, n, fds, cores);
for(int i=1; i<argc; i ){
cores = atoi(argv[i]);
splitter(0, n, fds, cores);
}
// nthread - calc
pipe(tfd);
threadSplitter(0, n, 16);
for(int i=1; i<argc; i ){
int threads = atoi(argv[i]);
threadSplitter(0, n, threads);
}
return 0;
}
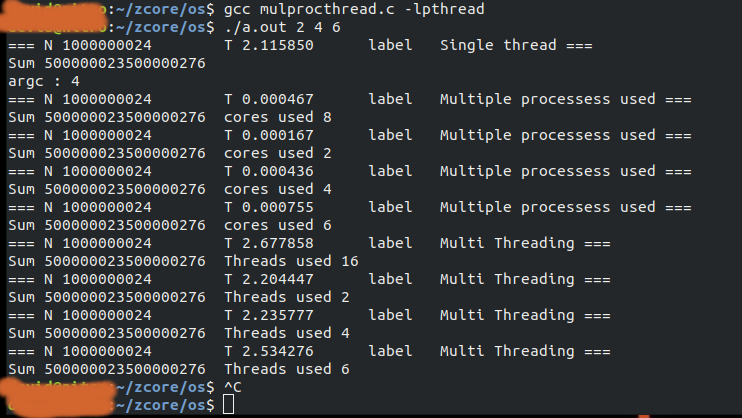
Output Results:
=== N 1000000024 T 2.115850 label Single thread ===
Sum 500000023500000276
argc : 4
=== N 1000000024 T 0.000467 label Multiple processess used ===
Sum 500000023500000276 cores used 8
=== N 1000000024 T 0.000167 label Multiple processess used ===
Sum 500000023500000276 cores used 2
=== N 1000000024 T 0.000436 label Multiple processess used ===
Sum 500000023500000276 cores used 4
=== N 1000000024 T 0.000755 label Multiple processess used ===
Sum 500000023500000276 cores used 6
=== N 1000000024 T 2.677858 label Multi Threading ===
Sum 500000023500000276 Threads used 16
=== N 1000000024 T 2.204447 label Multi Threading ===
Sum 500000023500000276 Threads used 2
=== N 1000000024 T 2.235777 label Multi Threading ===
Sum 500000023500000276 Threads used 4
=== N 1000000024 T 2.534276 label Multi Threading ===
Sum 500000023500000276 Threads used 6
Also, I have used pipe to transport the results of sub tasks. In multi-threading I have also tried to use join thread and sequentially merge the results but the final result was similar around 2 sec execution time.
Output:
CodePudding user response:
TL;DR: you are measuring time in the wrong way. Use clock_gettime(CLOCK_MONOTONIC, ...) instead of clock().
You are measuring time using clock(), which as stated on the manual page:
[...] returns an approximation of processor time used by the program. [...] The value returned is the CPU time used so far as a
clock_t
The system clock used by clock() measures CPU time, which is the time spent by the calling process while using the CPU. The CPU time used by a process is the sum of the CPU time used by all of its threads, but not its children, since those are different processes. See also: What specifically are wall-clock-time, user-cpu-time, and system-cpu-time in UNIX?
Therefore, the following happens in your 3 scenarios:
No parallelism, sequential code. The CPU time spent running the process is pretty much all there is to measure, and will be very similar to the actual wall-clock time spent. Note that CPU time of a single threaded program is always lower or equal than its wall-clock time.
Multiple child processes. Since you are creating child processes to do the actual work on behalf of the main (parent) process, the parent will use almost zero CPU time: the only thing that it has to do is a few syscalls to create the children and then a few syscalls to wait for them to exit. Most of its time is spent sleeping waiting for the children, not running on the CPU. The children processes are the one that run on the CPU, but you are not measuring their time at all. Therefore you end up with a very short time (1ms). You are basically not measuring anything at all here.
Multiple threads. Since you are creating N threads to do the work, and taking the CPU time in the main thread only, the CPU time of your process will account to the sum of CPU times of the threads. It should come to no surprise that if you are doing the exact same calculation, the average CPU time spent by each thread is T/NTHREADS, and summing them up will give you T/NTHREADS * NTHREADS = T. Indeed you are using roughly the same CPU time as the first scenario, only with a little bit of overhead for creating and managing the threads.
All of this can be solved in two ways:
- Carefully account for CPU time in the correct way in each thread/process and then proceed to sum or average the values as needed.
- Simply measure wall-clock time (i.e. real human time) instead of CPU time using
clock_gettimewith one ofCLOCK_REALTIME,CLOCK_MONOTONICorCLOCK_MONOTONIC_RAW. Refer to the manual page for more info.