I have a git repository on my local system in /original/.git. Now, I have cloned this repository in /cloned_one/.git. Everything looks fine. Here, I have the same files that I have in /original which is quite nice. I create a new file and commit it. Now, my cloned repo is one commit ahead. I want to push the changes but don't know how!
It becomes more tricky because I'm a bit confused about the following command's diversities and exact use-cases. I know some of them and actually worked with them somehow but I've seen a lot of users use them in the wrong place and that's what made me confused. Not sure when to use the following commands.
git fetchgit rebasegit pushgit mergegit --force push
Thanks.
CodePudding user response:
Git's remote repository can be from ssh, https, and directory.
In your example,
/original/.githave remote origin that points to github (either via ssh or https, e.g.:https://github.com/user/example.git)/cloned_one/.githave remote origin that points to directory (e.g.:/original/.git
This looks like some kind of linked list:
[/cloned_one/.git] --origin--> [/original/.git] --origin--> [github]
Here is an example command to reproduce such setup:
$ cd /tmp
$ git clone https://github.com/schacon/example.git original
Cloning into 'original'...
remote: Enumerating objects: 4, done.
remote: Total 4 (delta 0), reused 0 (delta 0), pack-reused 4
Receiving objects: 100% (4/4), 18.52 KiB | 3.70 MiB/s, done.
$ mkdir cloned_one
$ git clone /tmp/original cloned_one
Cloning into 'cloned_one'...
done.
$ cd cloned_one/
$ echo newfile > newfile.txt
$ git status
On branch master
Your branch is up to date with 'origin/master'.
Untracked files:
(use "git add <file>..." to include in what will be committed)
newfile.txt
nothing added to commit but untracked files present (use "git add" to track)
$ git add newfile.txt
$ git commit -m 'add new file'
[master e45e780] add new file
1 file changed, 1 insertion( )
create mode 100644 newfile.txt
$ git remote -v
origin /tmp/original (fetch)
origin /tmp/original (push)
$ git status
On branch master
Your branch is ahead of 'origin/master' by 1 commit.
(use "git push" to publish your local commits)
nothing to commit, working tree clean
Now, the cloned_one is 1 commit ahead of original
You can push changes from cloned_one to original with (remember to cd /tmp/cloned_one first):
git pushgit push origin mastergit push /tmp/original master
Here, the syntax of pushing is to specify where you want to push (e.g.: to origin, or to /tmp/original directory), and what branch you want to push
$ cd /tmp/cloned_one/
$ git status
On branch master
Your branch is ahead of 'origin/master' by 1 commit.
(use "git push" to publish your local commits)
nothing to commit, working tree clean
$ git push
Enumerating objects: 4, done.
Counting objects: 100% (4/4), done.
Delta compression using up to 8 threads
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 333 bytes | 333.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
remote: error: refusing to update checked out branch: refs/heads/master
remote: error: By default, updating the current branch in a non-bare repository
remote: is denied, because it will make the index and work tree inconsistent
remote: with what you pushed, and will require 'git reset --hard' to match
remote: the work tree to HEAD.
remote:
remote: You can set the 'receive.denyCurrentBranch' configuration variable
remote: to 'ignore' or 'warn' in the remote repository to allow pushing into
remote: its current branch; however, this is not recommended unless you
remote: arranged to update its work tree to match what you pushed in some
remote: other way.
remote:
remote: To squelch this message and still keep the default behaviour, set
remote: 'receive.denyCurrentBranch' configuration variable to 'refuse'.
To /tmp/original
! [remote rejected] master -> master (branch is currently checked out)
error: failed to push some refs to '/tmp/original'
Now it says that you have trouble pushing to /tmp/original because its not a bare repo. You can fix this by either changing /tmp/original to bare repo, or just configure it to update its worktree when being pushed to like below:
$ cd /tmp/original/
$ git config receive.denyCurrentBranch updateInstead
$ cd /tmp/cloned_one/
$ git push
Enumerating objects: 4, done.
Counting objects: 100% (4/4), done.
Delta compression using up to 8 threads
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 333 bytes | 333.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
To /tmp/original
c3d5e92..e45e780 master -> master
Now, if you want to push your changes back to github (the origin of /tmp/original) you can push it from /tmp/original or from /tmp/cloned_one:
cd /tmp/original ; git push origin mastercd /tmp/cloned_one ; git push https://github.com/username/example.git
Notice that when pushing from /tmp/original, you can specify the target as origin (since the origin of /tmp/original is from github). While when pushing from /tmp/cloned_one, you have to specify the target as full URL.
You can also change cloned_one's remote to point to github (search for git remote manual)
CodePudding user response:
All about Git Commands
TL;DR
To upload your changes to the repository you cloned, use git push. This applies even if you cloned a repository that was on your local machine.
Local Branches & Remote Branches
To understand things, a repository normally has two sets of branches:
- Your local branches
- The remote branches
Normally when you list branches with git branch, it only lists the local branches. But you can list all of them with git branch -a:
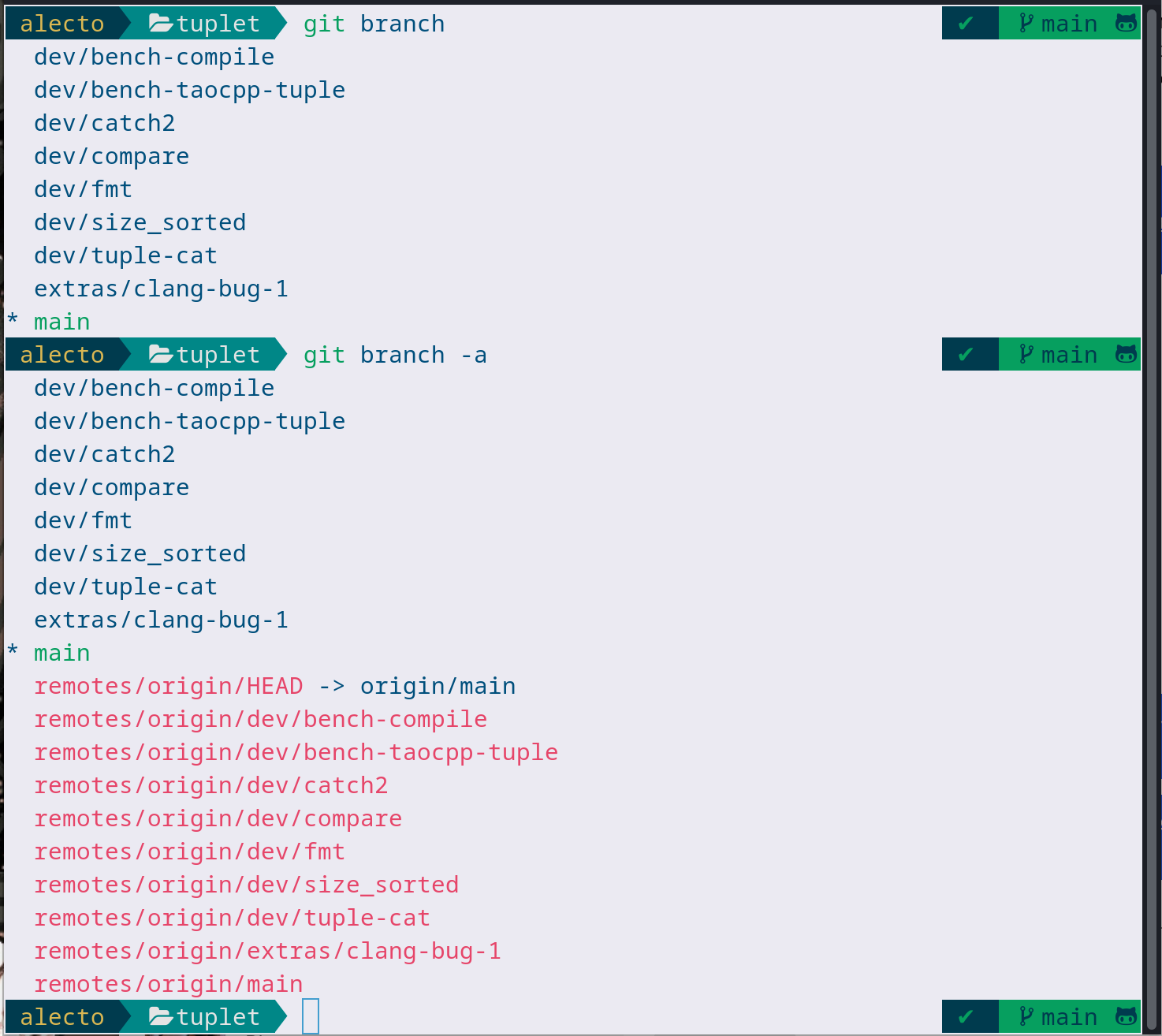
Here, this shows my local branches, as well as the remote branches (colored in red, to indicate that they're remote)
When you run git pull, this actually does two steps:
- First, it runs
git fetch. This will update all of the remote branches based on whatever's in the repo you cloned from. Note that this repo may not actually be on a remote server; it could be on your local machine, like in your case. - Second, it runs
git mergeorgit rebasedepending on your config options. This will merge your remote branches into your local branches.
That's how your repository is updated.
But would you ever fetch without merging?
Fetching without merging can be useful because it allows you to inspect remote changes before they're merged into your local branches. This can be done like so:
git fetch
git diff <your branch> origin/<your branch>
Running this in one of my repositories, I see the following changes have occured on the original repo I cloned from. (This uses 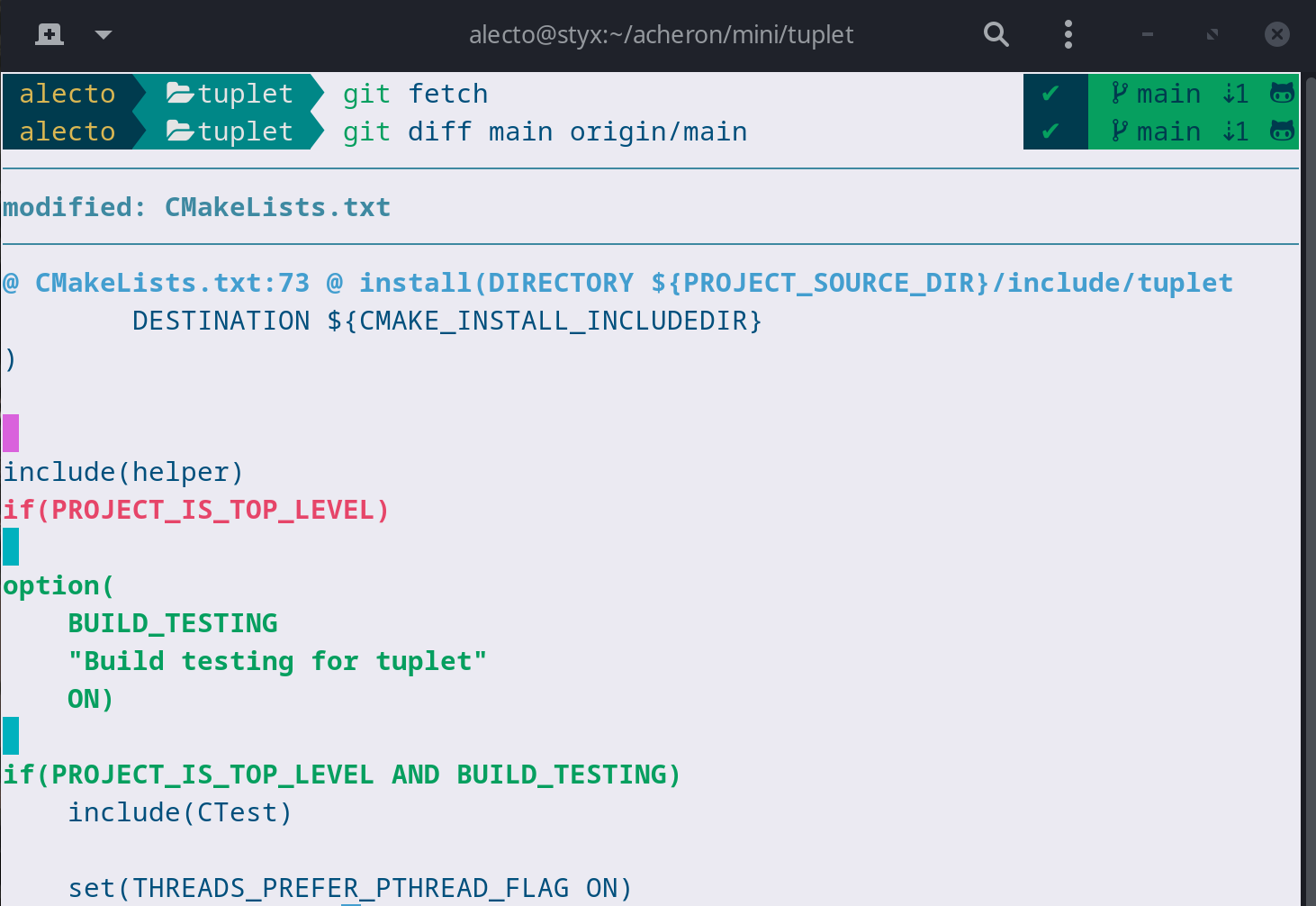
TL;DR: You don't usually need to fetch, but it's nice to view changes ahead of time
Merging vs Rebasing
Merging is when you take two separate histories, and join them together with a merge commit.
Most commits have a parent, but merge commits have two parents (or three or more, in the case of octopus merges). Initial commits have zero parents, but they're special because nothing comes before them.
We can take a look at the commit graph of one of the projects I'm working on to see an example of this. Here, I did work in several feature branches, before creating pull requests for them to be merged back into the main branch.
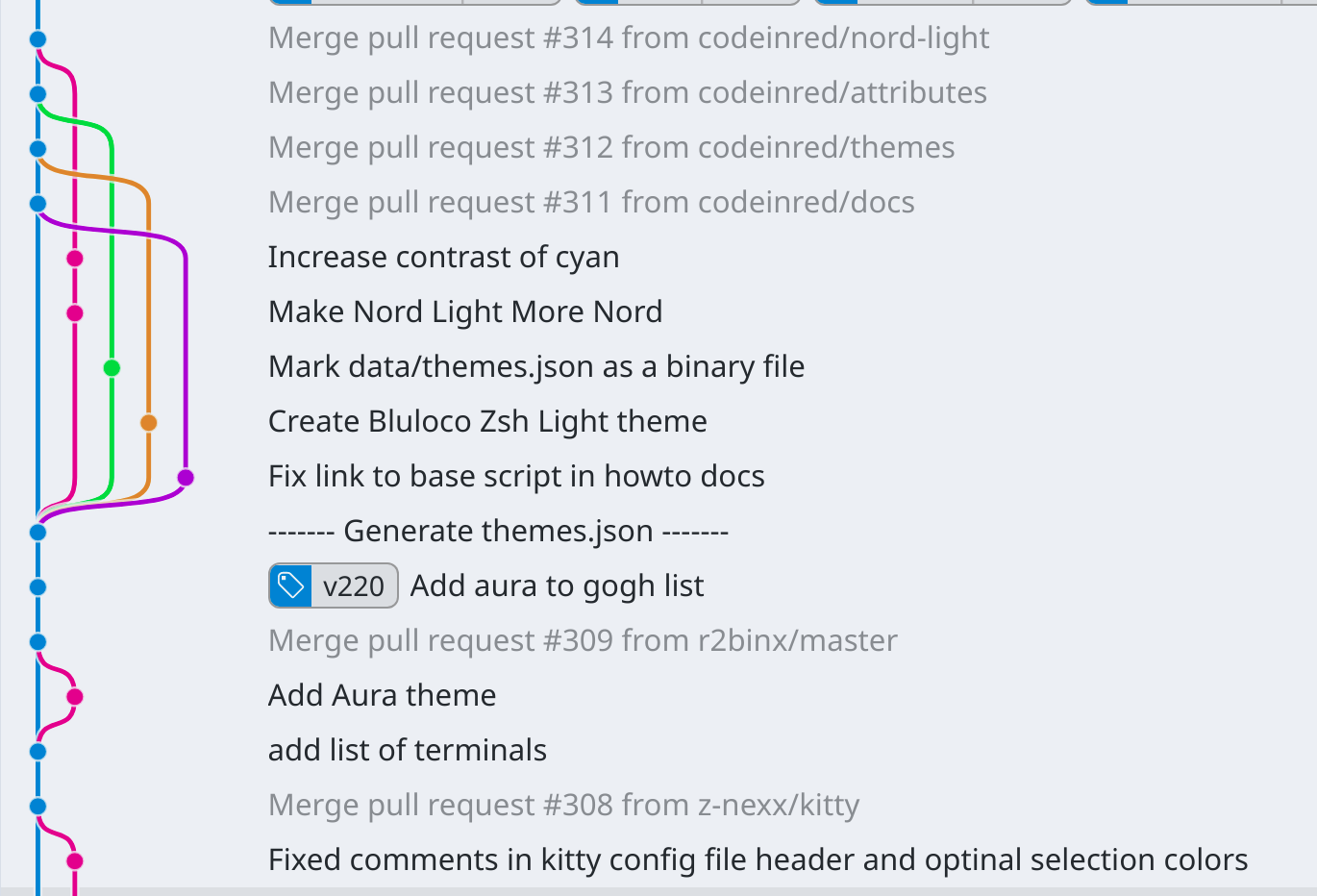
I think graphs like this are pretty, but some people prefer linear histories, and that's where re-basing comes in.
Instead of joining two branches together, it just breaks one branch off, and glues it on top of the other one. This is a good article that goes into detail about it.
What's pull with rebase?
If you have commits on your local branch (say, main), AND there are new commits on the remote branch (say, origin/main), then normally, as the final step in of the pull, git will merge the two, so that your local branch will now have all the commits from origin/main.
This is the one time I prefer rebasing to merging: it's nicer to just stick your local commits on top of the remote ones, so there aren't multiple branches in history.
I set rebasing as the default option using the following command:
git config --global pull.rebase merges
What this means is "rebase my local commits on top of the remote ones, but preserve any merges I did intentionally (like merging in a feature branch)". This is a good default to have, and it keeps me happy.
git push, and git push --force
This is how you get your local changes, to the cloned repository.
git push will upload your changes, but if the remote repository has changes you don't have (say, because a coworker pushed to it before you), it'll refuse to upload your changes since that would cause a conflict. Fixing this is simple:
git pull
git push
- Pulling integrates your coworker's changes with yours by either merging or rebasing, so that yours can be uploaded
- Pushing then uploads your changes
So what about git push --force?
Be very careful using this command. It's main purpose is to re-write history, which is occasionally necessary if secrets got committed to a git repository, or if you need to permanently remove a file for other reasons.
If your coworker has changes on the remote repository, force pushing will overwrite those changes.
If you want to overwrite commits you made, a safer option is --force-with-lease, which will ensure that the only changes being overwritten are yours.
CodePudding user response:
Here is how I like to think of this: Repositories share commits, but they don't share branch names.
A Git repository is, at its heart—the edges get all messy—really a pair of databases. Both databases are simple key-value stores:
One of them—usually the biggest by far—is indexed / accessed by big ugly hash IDs. These are commit hash IDs, and other internal Git object hash IDs. So this is the objects database (although Git doesn't normally refer to it this way).
The other one maps names—branch names, tag names, and all other kinds of names—to those big ugly hash IDs. This lets us poor humans use Git; the hash IDs are not usable. This is the names database, and each name maps to exactly one hash ID. More than one name can map to one particular hash ID, and many hash IDs have no name that maps to them, so if you're used to thinking in terms of mathematical sets, this is a non-injective, non-surjective mapping (see surjective function).
Each commit object in the objects database has a unique hash ID. The hash ID of any object, commit or not, is the result of running a cryptographic hash function over the data that make up the object (this is how Git does its consistency checking and its file-content-de-duplication). But each commit is itself unique, thanks to several properties of a commit, so each one gets a unique hash ID.1 Using these commit hash IDs, then, any two different Git repositories, using compatible Git software—I call these "two Gits"—the two Gits can immediately tell whether they have the same commits or not, just by comparing commit hash IDs.2
What this all boils down to is that when we hook two Gits to each other, one—the sender—says things like I have commit a123456..., would you like it? to which the other replies either yes please or no thanks, I have that one already, and this allows the sender to send to the receiver just the commits the sender has that the receiver lacks.
This process—of sending commits I have that you don't, for instance—is a git fetch or git push, depending on who starts the conversation. If you start the conversation to get commits from me, you are using git fetch. If I start the conversation to send commits to you, I am using git push.
1Anyone familiar with the pigeonhole principle will immediately object that a hash function, even one with a 2160 range (SHA-1) or 2256 range (SHA-256), must eventually produce a collision. This is true, and when that happens, Git stops functioning, so the hashes must be big enough that "eventually" is enough decades or centuries away not to worry. (Due to the birthday problem, this is harder than it might seem at first.)
2Due to the DAG that the commits form, we can do much better than just listing out all raw hash IDs, but if we had two fairly small repositories—say a few thousand commits each—it would be easy enough to just list all the hash IDs, to see who has which commits.
That's most of what there is to using more than one Git repository
Seriously, this kind of transfer is all we need, and is all there was in primeval Git, for connecting two Gits to each other. By comparing hash IDs and sending commits I have that you don't, you wind up sharing my commits. If I then turn around and get, from you, any commits you have that I don't, we're now equal in terms of the set of commits we have. But this isn't a convenient way to use Git, so we now add a few extras.
Branch names, tag names, remote-tracking names, and so on
Humans are bad at hash IDs: e9e5ba39a78c8f5057262d49e261b42a8660d5b9. Say what? There are probably a few people who can repeat back to you a list of Git-repository-for-Git tag hash IDs, if they've read them, but I for one will transpose the characters sometimes, and don't bother trying to memorize them. That's what the computer is for. I let the computer remember the hash IDs for me: master might hold e9e5ba39a78c8f5057262d49e261b42a8660d5b9 right now. Later, master will hold some other hash ID. Whatever hash ID it holds, that is, by definition, the latest commit on my master branch in this Git repository.
When we use git fetch, Git maintains all of this stuff for us in a nice way. We create a remote—a short name like origin—under which we store a conventional URL such as ssh://[email protected]/path/to/repo.git, or a pathname like /absolute/path/to/dir/.git, or whatever is appropriate.3
Now that we have this short name, origin or fred or whatever we choose, our Git can call up their Git—that is, our Git software can use ssh or https or whatever, to reach out to their Git software; our Git will operate in our repository, and their Git will operate in their repository—and once we've called up their Git, we can use git fetch to get commits from them. We do this with a simple:
git fetch origin
for instance.
Their Git lists out their branch names and the corresponding commit hash IDs. Our Git inspects these hash IDs and uses that to figure out if they have commits that we don't. If we don't limit our Git,4 our Git now brings over all of their commits that we don't already have, so now we share their commits.
But: our branch names are stuff we use to find specific commits in our repository, that we like for some specific reason. Our git fetch does not touch our branch names. Instead, our Git takes each of their branch names and changes these into remote-tracking names.5 Git does this by sticking the remote name—in this case, origin—in front of the branch name, plus a slash. So this is where origin/main or origin/master comes from: that's our copy of their branch name. It's our Git's way of remembering their Git's main or master (whichever one they have).
So, git fetch gets us their commits, but does nothing with our own branches. Due to the hashing tricks that Git uses, all objects—including all commits—are completely read-only, so this update only adds new commits to our repository. We share their commits but not their branch names.
3A very short relative path like ../d/.git isn't much longer or harder to type than origin, so for this kind of case, you might be tempted to leave out the remote name. But don't do it! Git needs that remote name to form the remote-tracking names. If you skip using a remote name, you're using the primeval mode, which Git still supports, it's just a pain in the <insert body part>.
4You can deliberately limit your git fetch to cut down on network traffic or whatever. This is mostly unnecessary most of the time, since Git is clever about only bringing over any needed objects. In some rare cases it can be useful, though.
5Git calls these remote-tracking branch names. They're not branch names though, not in our repository anyway. They're our copies of someone else's branch names. So from our point of view these are non-branch names that merely happen to "track" someone else's (branch) names. Git over-uses both the verb track and the adjective branch, but we can cut down this overuse just a smidgen here.
From this point on, you work locally, at least until git push
What you have at this point is:
- all the commits;
- your own branch names; and
- your copy / memory of their branch names.
You work with your repository by extracting specific commits (git checkout) into your working tree and Git's index or staging area (two terms for the same thing). You eventually make new commits, which add on to the existing commits. When you do make a new commit, Git automatically updates your current branch name, so that your branch names automatically include your new commits.
You've asked about merge and rebase, and these are both actually quite large topics, but they're pretty well covered elsewhere. Remember that git merge mostly means combine work. Though git merge is full of exceptions to the usual ways of combining work, this mostly happens by making new commits. Meanwhile, git rebase means I'm sort of satisfied with some set of commits in my repository, but there is something I don't like about these commits. I'd like to copy them to a set of new-and-improved commits, with the option of doing special tricks along the way.
Because you literally can't change any existing commit, the copying means that you get duplicates—or rather, near-duplicates, with the "near" part depending on what you're changing, given that you're changing something or you'd just use the originals. The goal of rebase is to stop using the originals and start using the near-duplicates instead. Since we generally find our commits using a branch name, Git achieves this by moving the name:
K--L <-- br2 (originals)
/
...--F--G--H--I--J <-- br1
\
K'-L' <-- proposed new br2
<-- older ... newer -->
We have Git copy K to K', improving the copy by using J as the base commit, then we have Git copy L to L', improving the copy by using K' as the base for L'. That's the main part of the rebase in action. But now we have to stop using K-L, and start using K'-L' instead. Since we find commits through branch names, Git merely needs to "peel the label" off commit L and paste it onto commit L' instead. Git then works backwards—this is a general theme in Git, that it starts at the end and works its way backwards—from L', so now you don't see K-L any more.
Because commits are shared and branch names aren't, if you got commits K-L from some other Git repository, you now have a problem: their branch name still refers to commit L, not to your new L'.
git push is not just a reversed git fetch
When you run git push, you:
- have your Git call up some other Git;
- have your Git give that Git specific commits: not just everything I have that you don't but rather every commit on some branch that I have that you don't (commits I have that you don't, that are on some particular branch of my choice);
- and finally, once those commits have made it over, you politely request (regular
git push) or command (git push --force) that their Git should update their branch name.
When we use git fetch, we have these friendly remote-tracking names by which our Git remembers their branch names. The push command doesn't bother with friendliness. We just propose to overwrite their branch name entirely, with some new hash ID.
If the commits we send to them add on to their branch as they see it right then and there, this polite request—please set your branch name develop to a123456... for instance—is probably OK. They had:
...--G--H <-- develop
where H stands in for 9876543... or whatever hash ID. We sent them commits I-J:
...--G--H <-- develop
\
I--J <-- polite request to set "develop" to point to J
If they obey this polite request, their commit H remains findable, because Git works backwards from the branch name's commit. J leads back to I which leads back to H, and hey, we haven't lost them any commits!
After a git rebase, though, we've taken some existing commits and thrown them out in favor of new-and-improved replacements. Suppose they had:
I--J <-- br1
/
...--F--G--H <-- develop
\
K--L <-- br2
in their repository, and we now send them a pair of commits K'-L' that add on to commit J:
K'-L' <-- please set br2 here
/
I--J <-- br1
/
...--F--G--H <-- develop
\
K--L <-- br2
This polite request, that they set their br2 to point to L' instead of L, will not go over well. They will say: No! If I do that I lose commits! Of course, we want them to lose K-L, in favor of K'-L'. But they don't know that unless we tell them.
This is what git push --force is for. However, if their Git repository is highly active, maybe we got K-L earlier, but now they have:
K'-L' <-- please set br2 here
/
I--J <-- br1
/
...--F--G--H <-- develop
\
K--L--N <-- br2
We're proposing that they ditch the entire K-L-N chain in favor of our K'-L'.
The --force-with-lease option is an attempt to improve this situation. It works pretty well in current Git, but there may be updates coming where it won't be quite right. (I think it should be kept "right", and there are proposals to do that too, so we'll see.)
Bare repositories
When we use Git, we have some commit checked out. This commit is from our current branch and is our current commit. We may be in the middle of working on a new commit. In this state, Git literally can't receive an update to our current branch: that would mess things up.6 So Git will deny a push to the currently-checked-out branch.
To sidestep this problem, Git repositories that are meant to receive git push requests are normally set up as bare repositories. A bare repository is one with no working tree. With no working tree, no one can do any work in the bare repository. This means there is nothing to get messed up, and the bare repository can always receive a push.
There are other ways to deal with this (configuration settings for receive.denyCurrentBranch), but another good way to sidestep the problem is to avoid git push: use git fetch when using two different repositories where you control both of them. By always fetching from B when you're in working in A, and always fetching from A when you're working in B, you can't step on yourself.
6In particular, Git's index contains an image of the current commit, as modified by any proposed replacement files we git add-ed, new files we added, and/or files we git rm-ed. Git will build the new commit from whatever is in the index, and the parent of the new commit will be the current commit, whose hash ID is stored in the branch name. So making an update to the branch name requires updating the index and working tree as well. If we're in the middle of doing something, that's a bad idea. Even if we're not, updating the branch name means that our new commit may go where we didn't expect. The whole situation is tough.
A bottom line
In Git, you work locally, with commits. These are in your repository: there's just the one, which you're in right now, with the one working tree and Git's index.7 To get commits from some other Git, use git fetch with a remote: a short name like origin. Add more remotes, with git remote add, to add more places to fetch from. Use git remote set-url to fiddle with the URL for one particular remote, git remote remove to remove a remote, and git remote update to make Git fetch from all remotes.8 Consider setting fetch.prune to true to work around what I consider a historical error in the fetch defaults.9
After you git fetch, you have all the commits. Do whatever you like with them. Leave them in your repository, rebase them, whatever. Then, if the other Git is a bare Git that's set up to receive git push requests, use git push to send your new commits and ask them to set one of their branch names to remember your commits:
- If this creates a new name in their Git, they'll probably allow it.
- If this updates a name such that the old commits are still there, they'll probably allow it.
- If this updates a name so as to stop finding old commits on their side, they will reject it unless you use one of the
--forceoptions; use--force-with-leasefor safety.
If the other Git isn't bare, and/or you want to work directly in it, change where you're working so that you're now in the other repository, and use git fetch to obtain the commits you made in the repository you were working in, a moment ago. Since fetch itself is always safe,10 this will be safe.
Always, always remember that if you haven't committed something, it's not in Git (yet). If you have committed it, it's in a commit, and even after mini-disasters, you can usually get it back.11
7git worktree add complicates this picture, so let's just ignore it here.