This is a toy public table in google BigQuery:
The table contains the names given to people in the US at birth and the frequency of those names for each state and year from 1910 to 2020
Columns: name, year, state, number, gender
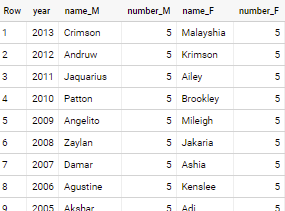
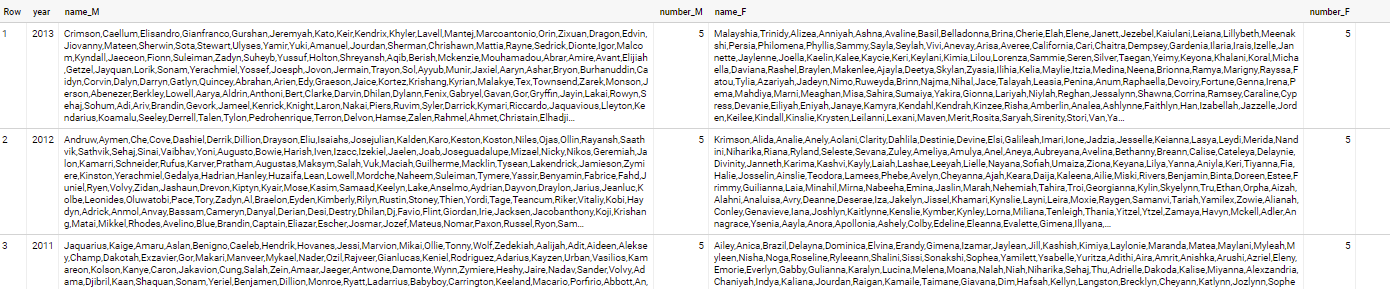
In reality - there are many names that have same least frequency - to get all of them - use below approach
select * from (
select year, gender, name, sum(number) number
from `bigquery-public-data.usa_names.usa_1910_2013`
group by year, gender, name
qualify 1 = dense_rank() over(partition by year, gender order by number)
)
pivot (string_agg(name) name, any_value(number) number for gender in ('M', 'F'))
with output
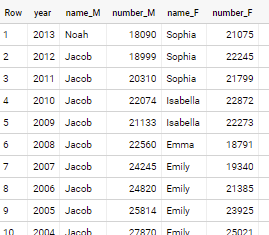
while if you would look for most frequent - you would use below
select * from (
select year, gender, name, sum(number) number
from `bigquery-public-data.usa_names.usa_1910_2013`
group by year, gender, name
qualify 1 = dense_rank() over(partition by year, gender order by number desc)
)
pivot (string_agg(name) name, any_value(number) number for gender in ('M', 'F'))
with just one most frequent name per year/gender