Hi I am a bit new to Python and am a bit confused how to proceed. I have a large dataset that contains both parent and child information. For example, if we have various items and their components, and their components also have other components or children, how do we create a type of tree structure? Here is an example of the data:
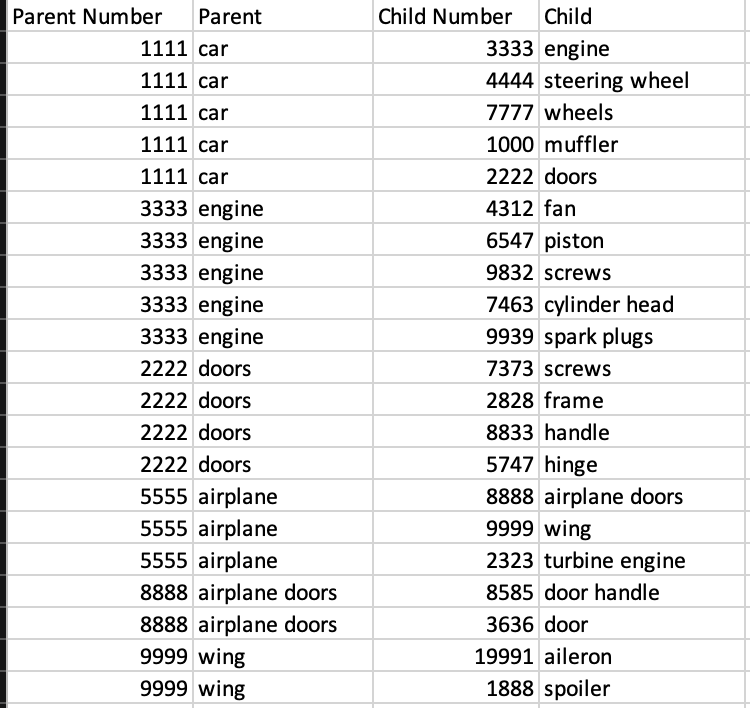
I was wondering how I can get it into a tree structure. So the output would be:
{kind=link}
and it will also return the one for airplane, similar to the one for car.
I know that the common attribute for this would be based upon the parent number/child number. But, I am a bit confused on how to go about this in python.
CodePudding user response:
Use a class to encode the structure:
class TreeNode:
def __init__(self, number, name):
self.number = number
self.name = name
self.children = []
def addChild(self, child):
self.children.append(child)
One example of how to use it:
car = TreeNode(1111, "car")
engine = TreeNode(3333, "engine")
car.addChild(engine)
Note: The number attribute doesn't have to be an int (e.g. 1111 for car); it can just as well be a string of the integer (i.e. "1111").
To actually get something resembling your desired output, we'll need to serialize the root object into nested dictionaries:
class TreeNode:
def __init__(self, number, name):
self.number = number
self.name = name
self.children = []
def addChild(self, child):
self.children.append(child)
def serialize(self):
s = {}
for child in self.children:
s[child.name] = child.serialize()
return s
Now, we can get something resembling your desired output by using json.dumps:
dummy = TreeNode(None, None) # think of this as the root/table
car = TreeNode(1111, "car")
dummy.addChild(car)
engine = TreeNode(3333, "engine")
car.addChild(engine)
fan = TreeNode(4312, "fan")
engine.addChild(fan)
print(json.dumps(dummy.serialize(), indent=4))
prints:
{
"car": {
"engine": {
"fan": {}
}
}
}
CodePudding user response:
Problems like this always come down to algorithm and data set. The first thing I notice about your data set is that it is ordered such that no child is ever the parent of a previous parent. In other words, the items are listed in a "top-down" fashion. Is this always to be true? If it is, it means the logic of the algorithm becomes much simpler.
Another consideration is data structure. I would use nested dictionaries to hold the main data set here. Each new unique parent will be a "key" of the main dict. And each "value" corresponding to that key will be a dict, and the nesting can continue on and on as needed. In this case, there will only be few levels of nesting.
So, for each line in the data set, you would check if the Parent appears as a key in the top dict or any of the nested dicts. If it does not, you'll create a new entry in the top level dict with Parent as the key, and {Child:{}} as the new entry's value. (This will happen for "car" and "airplane".)
If the current Parent DOES appear as a key in any of the dicts, you need to add the Child value as a new key to the dict that is the value of the dict which has Parent as a key. In that instance, Child is the new key, and the value for that key is the empty dict {}.
The above is the rough logic I would use to write the code. I leave that part to you. There may be third party libraries you can use to make the effort much less, but if you're taking a class and this is an assignment, your teacher may not want you to use such external libraries.
Note that the above logic assumes that the data set is organized as "top-down." If that is not the case, then the logic becomes more complicated, and a key that is currently at a certain level in the hierarchy might be bumped down the hierarchy if a new Parent to that Child is processed in the data set.