I want to plot a stacked bar plot with seaborn or matplotlib. I want to get all my needed information with .pivot_table and then I want to filter only the three neighbourhoods with the most counts. But there is an KeyError: 'neighbourhood' because neighbourhood is index in df_new.
How could I generate from my df_new (df.pivot_table must be) a stacked bar plot with only the top three neighbourhoods?
d = {'host_id': [1, 1, 2, 3, 3],
'listing_id': [1, 2, 3, 4, 5],
'neighbourhood': ['Sofia', 'New York', 'Berlin', 'London', 'London'],
'price': [50.0, 60.0, 50.0, 80.0, 90.0],
'room_type': ['Private', 'Private', 'Shared', 'Private', 'Shared']}
df = pd.DataFrame(data=d)
print(df)
[OUT]
host_id listing_id neighbourhood price room_type
0 1 1 Sofia 50.0 Private
1 1 2 New York 60.0 Private
2 2 3 Berlin 50.0 Shared
3 3 4 London 80.0 Private
4 3 5 London 90.0 Shared
df_new = df.pivot_table(index='neighbourhood', columns='room_type',
values='price', aggfunc='mean',
fill_value=0.0)
print(df_new)
[OUT]
room_type Private Shared
neighbourhood
Berlin 0 50
London 80 90
New York 60 0
Sofia 50 0
df_Best = df.groupby(["neighbourhood"])["room_type"].count().reset_index(
name="count").sort_values(
by=['count'], ascending=False).head(3)
print(df_Best)
[OUT]
neighbourhood count
1 London 2
0 Berlin 1
2 New York 1
df_new.loc[df_new['neighbourhood'].isin(df_Best['neighbourhood'].head(1).values[0])]
print(df_new)
[OUT]
KeyError: 'neighbourhood'
# Because neighbourhood is index in df_new
At the end I want something like
CodePudding user response:
You could use the "neighbourhood" column of df_Best to directly index df_new. E.g. df_new.loc[df_Best['neighbourhood'].head(1)].
from matplotlib import pyplot as plt
import pandas as pd
d = {'host_id': [1, 1, 2, 3, 3],
'listing_id': [1, 2, 3, 4, 5],
'neighbourhood': ['Sofia', 'New York', 'Berlin', 'London', 'London'],
'price': [50.0, 60.0, 50.0, 80.0, 90.0],
'room_type': ['Private', 'Private', 'Shared', 'Private', 'Shared']}
df = pd.DataFrame(data=d)
df_new = df.pivot_table(index='neighbourhood', columns='room_type',
values='price', aggfunc='mean',
fill_value=0.0)
df_Best = df.groupby(["neighbourhood"])["room_type"].count().reset_index(
name="count").sort_values(
by=['count'], ascending=False).head(3)
df_new.loc[df_Best['neighbourhood']].plot.bar(stacked=True, rot=0)
plt.show()
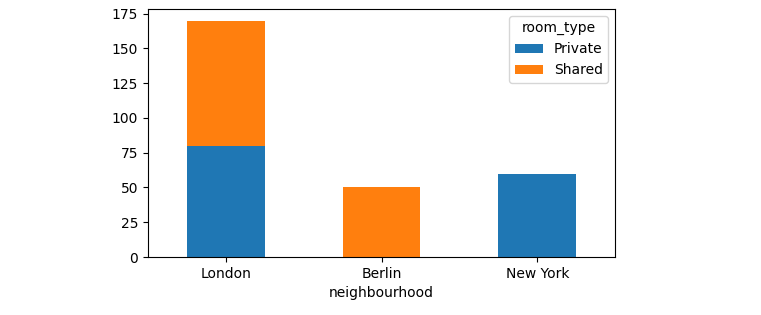
Note that df_new is created via df.pivot_table(...).
If you really want to create the plot purely from df.pivot_table, a less readable form would be:
df.pivot_table(index='neighbourhood', columns='room_type', values='price', aggfunc='mean',
fill_value=0.0).loc[
df.groupby(["neighbourhood"])["room_type"].count().sort_values(ascending=False).head(3).index]