UPDATE Added Read/Write Throughput, IOPS, and Queue-Depth graphs metrics and marked graph at time-position where errors I speak of started
NOTE: Hi, just looking for suggestions of what could possibly be causing this issue from experienced DBA or database developers (or anyone that would have knowledge for that matter). Some of the logs/data I have are sensitive, so I cannot repost here but I did my best to provide screen shots and data from my debugging so it would allow people to help me. Thank you.
Hello, I have a Postgres RDS database (version 12.7 engine) that is hosted on Amazon (AWS). This database is "hit" or called by a API client (Spring Boot/Web/Hibernate/JPA Java API) thousands of times per hour. It is only executing one 1 hibernate sql query on the backend that is on a Postgres View across 5 tables. queryDB instance (class = db.m5.2xlarge) specs are:
8 vCPU
32 GB RAM
Provisioned IOPS SSD Storage Type
800 GiB Storage
15000 Provisioned IOPS
The issue I am seeing is on Saturdays I wake up to many logs of JDBCConnectionExceptions and I noticed my API Docker containers (Defined as Service-Task on ECS) which are hosted on AWS Elastic Container Service (ECS) will start failing and return a HTTP 503 error, e.g.
org.springframework.dao.DataAccessResourceFailureException: Unable to acquire JDBC Connection; nested exception is org.hibernate.exception.JDBCConnectionException: Unable to acquire JDBC Connection
Upon checking AWS RDS DB status, I can see also the sessions/connections increase dramatically, as seen in image below with ~600 connections. It will keep increasing, seeming to not stop.

Upon checking the postgres database pg_locks and pg_stat_activity tables when I started getting all these JDBCConnectionExceptions and the DB Connections jumped to around ~400 (at this specific time), I did indeed see many of my API queries logged with interesting statuses. I exported the data to CSV and have included an excerpt below:
wait_event_type wait_event state. query
--------------- ------------ --------------------------------------------- -----
IO DataFileRead active (480 times logged in pg_stat_activity) SELECT * ... FROM ... query from API on postgres View
IO DataFileRead idle (13 times logged in pg_stat_activity) SELECT * ... FROM ... query from API on postgres View
IO DataFilePreFetch active (57 times logged in pg_stat_activity) SELECT * ... FROM ... query from API on postgres View
IO DataFilePreFetch idle (2 times logged in pg_stat_activity) SELECT * ... FROM ... query from API on postgres View
Client ClientRead idle (196 times logged in pg_stat_activity) SELECT * ... FROM ... query from API on postgres View
Client ClientRead active (10 times logged in pg_stat_activity) SELECT * ... FROM ... query from API on postgres View
LWLock BufferIO idle (1 times logged in pg_stat_activity) SELECT * ... FROM ... query from API on postgres View
LWLock BufferIO active (7 times logged in pg_stat_activity) SELECT * ... FROM ... query from API on postgres View
If I look at my pg_stats_activity table when my API and DB are running and stable, the majority of the rows from the API query are simply Client ClientRead idle status, so I feel something is wrong here.
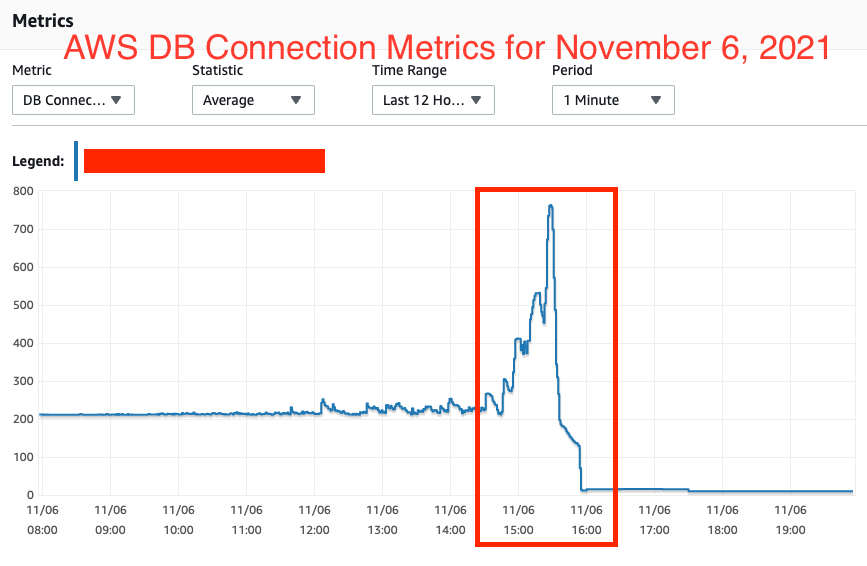
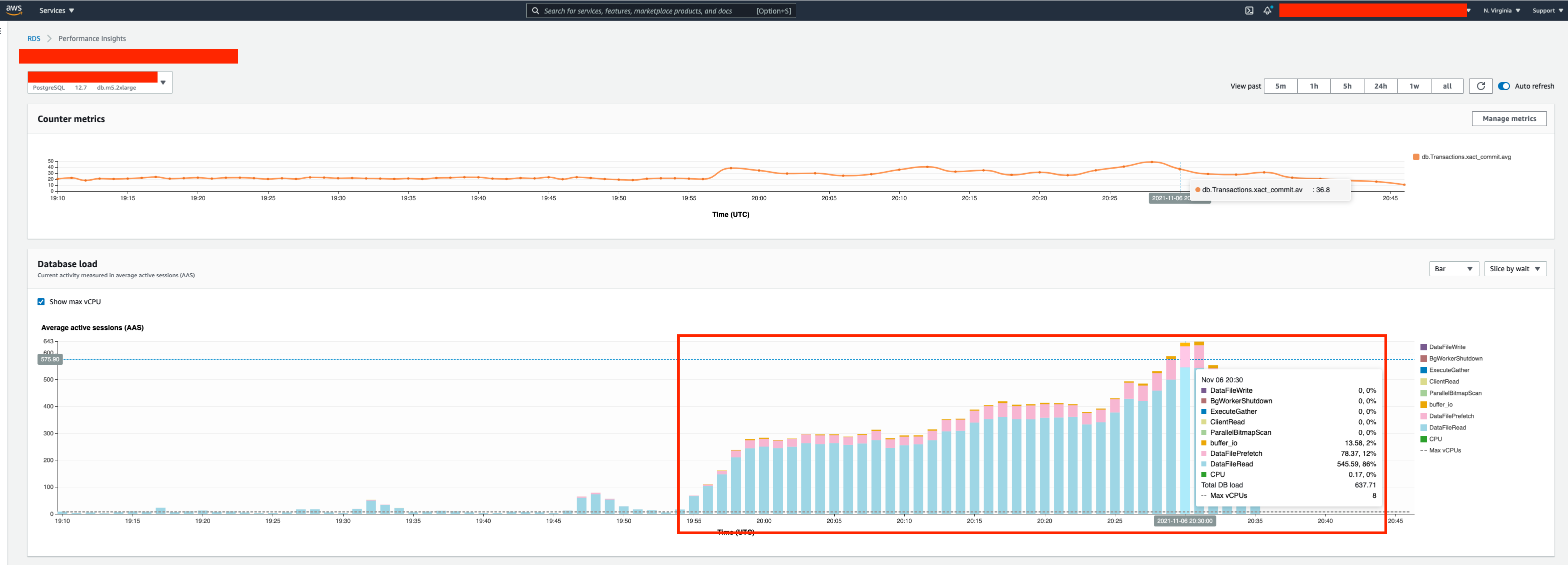
You can see the below "performance metrics" on the DB at the time this happened (i.e. roughly 19:55 UTC or 2:55PM CST), the DataFileRead and DataFilePrefetch are astronomically high and keep increasing, which backs up the pg_stat_activity data I posted above. Also, as I stated above, during normal DB use when it is stable, the API queries will simply be in Client ClientRead Idle status in pg_stat_activity table, the the numerous DataFileRead/Prefetches/IO and ExclusiveLocks confuses me.
I don't expect anyone to debug this for me, though I would appreciate it if a DBA or someone who has experienced similiar could narrow down the issue possibly for me. I honestly wasn't sure if it was an API query taking too long (wouldn't make sense, because API has ben running stable for years), something running on the Postgres DB without my knowledge on Saturday (I really think something like this is going on), or a bad postgresql Query coming into the DB that LOCKS UP the resources and causes a deadlock (doesn't completely make sense to me as I read Postgres resolves deadlocks on its own). Also, as I stated before, all the API calls that make an SQL query on the backend are just doing SELECT ... FROM ... on a Postgres VIEW, and from what I understand, you can do concurrent SELECTS with ExclusiveLocks so.....
Would take any advice here or suggestions for possible causes of this issue
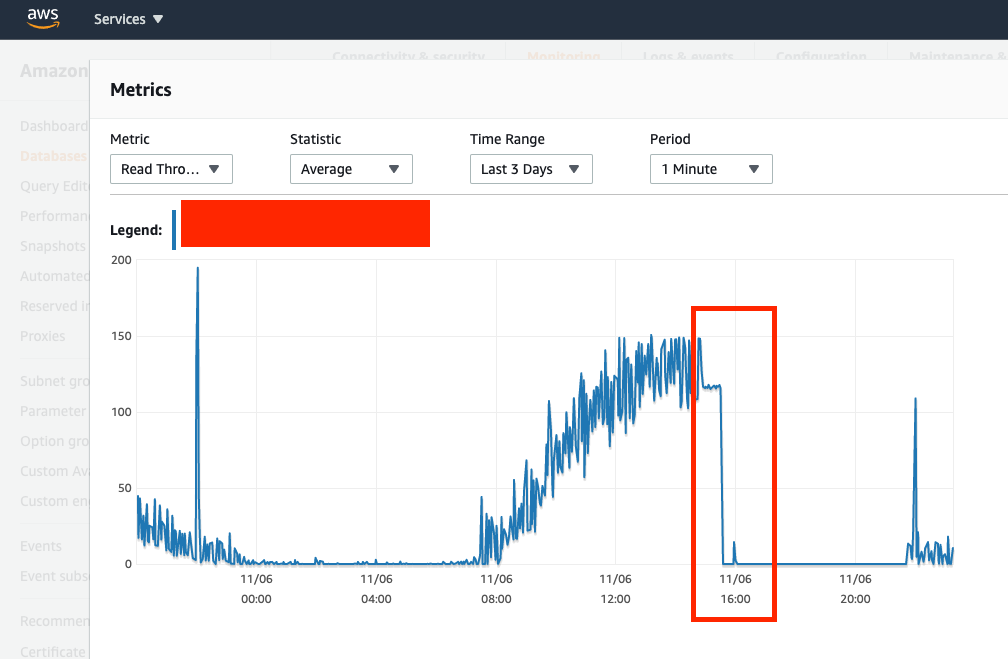
Read-Throughput (first JdbcConnectionException occured around 2:58PM CST or 14:58, so I marked the graph where READ throughput starts to drop since the DB queries are timing out and API containers are failing)
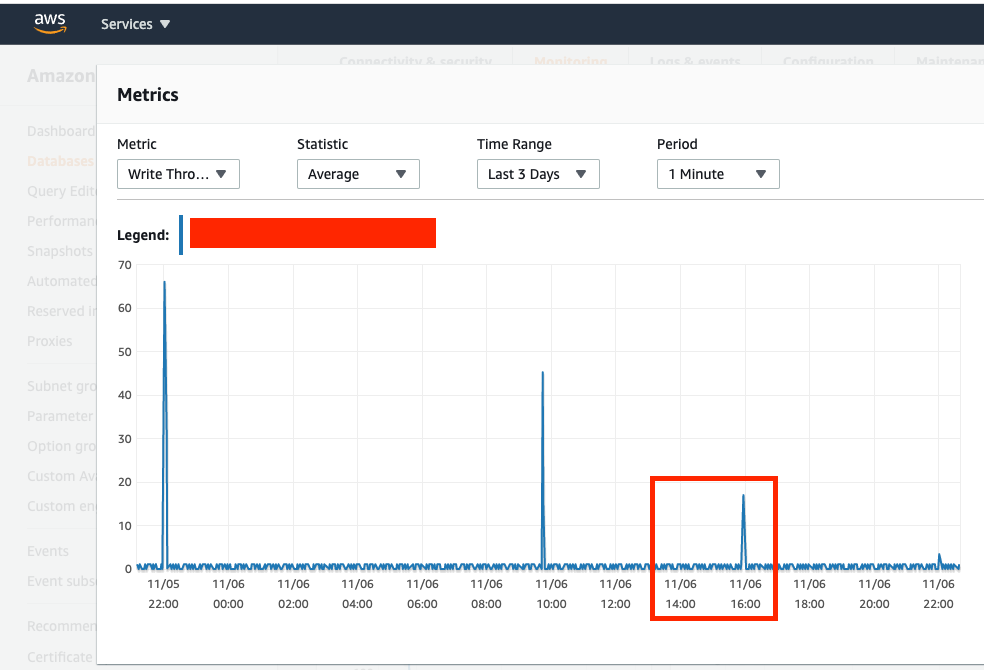
Write-Throughput (API only READS so I'm assuming spikes here are for writing to Replica RDS to keep in-sync)
Total IOPS (IOPS gradually increasing from morning i.e. 8AM, but that is expected as API calls were increasing, but these total counts of API calls match other days when there are 0 issues so doesn't really point to cause of this issue)
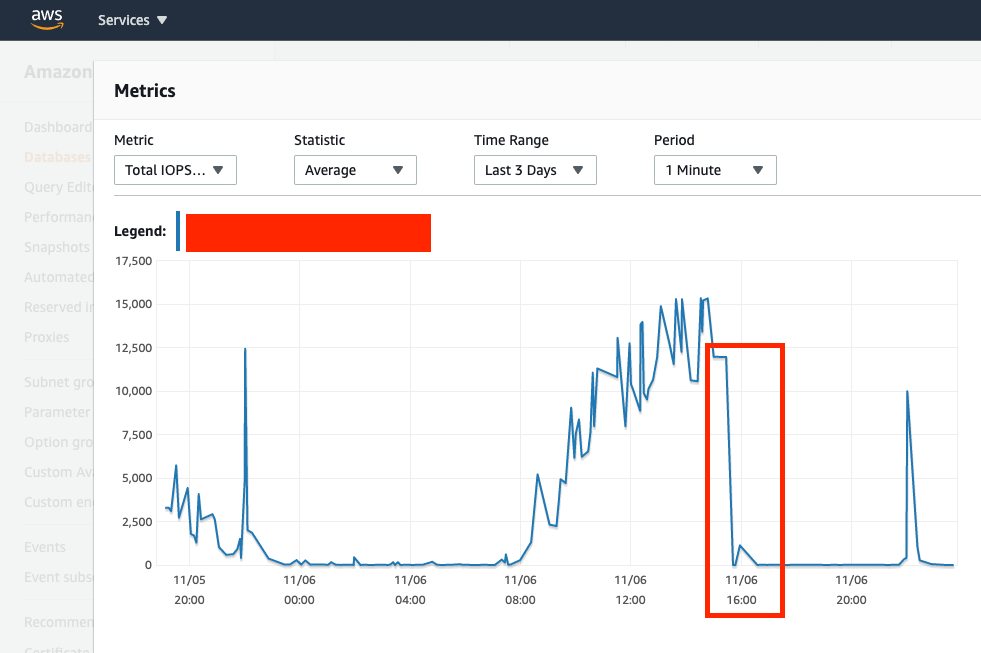
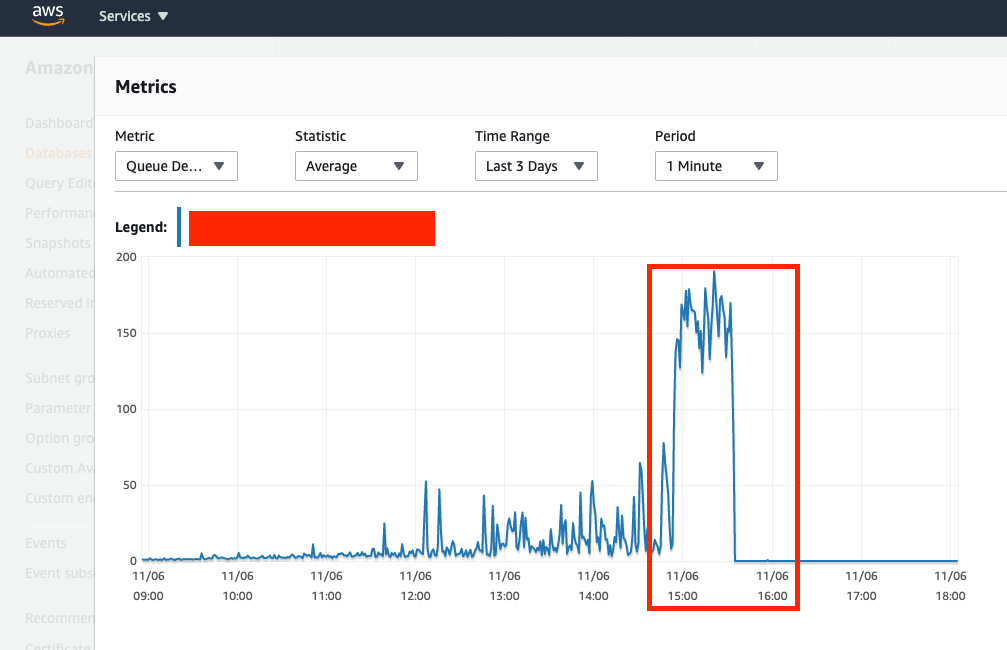
Queue-Depth (you can see where I marked graph and where it spikes is exactly around 14:58 or 2:58PM where first JdbcConnectionExceptions start occuring, API queries start timing out, and Db connections start to increase exponentially)
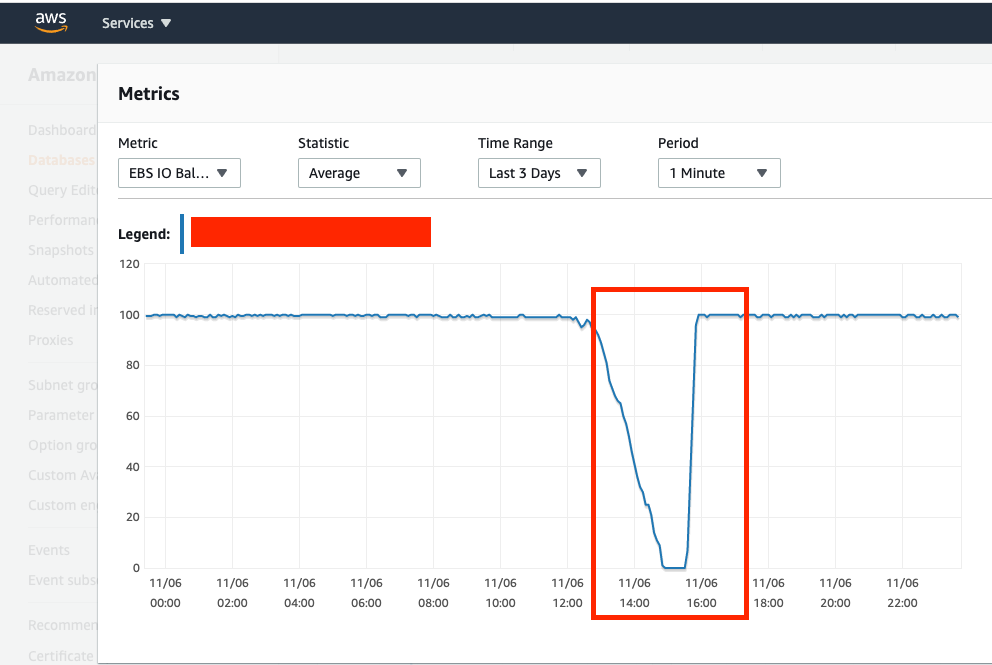
EBS IO Balance (burst balance basically dropped to 0 at this time as-well)
Performance Insights (DataFileRead, DataFilePrefetch, buffer_io, etc)
CodePudding user response:
This just looks like your app server is getting more and more demanding and the database can't keep up. Most of the rest of your observations are just a natural consequence of that. Why it is happening is probably best investigated from the app server, not from the database server. Either it is making more and more requests, or each one is takes more IO to fulfill. (You could maybe fix this on the database by making it more efficient, like adding a missing index, but that would require you sharing the query and/or its execution plan).
It looks like your app server is configured to maintain 200 connections at all times, even if almost all of them are idle. So, that is what it does.
And that is what ClientRead wait_event is, it is just sitting there idle trying to read the next request from the client but is not getting any. There are probably a handful of other connections which are actively receiving and processing requests, doing all the real work but occupying a small fraction of pg_stat_activity. All of those extra idle connections aren't doing any good. But they probably aren't doing any real harm either, other than making pg_stat_activity look untidy, and confusing you.
But once the app server starts generating requests faster than they can be serviced, the in-flight requests start piling up, and the app server is configured to keep adding more and more connections. But you can't bully the disk drives into delivering more throughput just by opening more connections (at least not once you have met a certain threshold where it is fully saturated). So the more active connections you have, the more they have to divide the same amount of IO between them, and the slower each one gets. Having these 700 extra connections all waiting isn't going to make the data arrive faster. Having more connections isn't doing any good, and is probably doing some harm as it creates contention and dealing with contention is itself a resource drain.
The ExclusiveLocks you mention are probably the locks each active session has on its own transaction ID. They wouldn't be a cause of problems, just an indication you have a lot of active sessions.
The BufferIO is what you get when two sessions want the exact same data at the same time. One asks for the data (DataFileRead) and the other asks to be notified when the first one is done (BufferIO).
CodePudding user response:
Based on what you've shared I would guess your connections are not being properly closed.