i've got a 3d space containing three clusters, but when I perform a clustering with Sklearn.cluster Kmeans, the results arn't so good. here is the code and results. hope you can help :)
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
km = KMeans(n_clusters=3)
y_predicted = km.fit_predict(df1[['x','y','z']])
y_predicted
def create_3d_scatter_wprd(df):
fig = plt.figure(figsize=(48, 24))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(df['x'], df['y'], df['z'], c=y_predicted)
plt.show()
create_3d_scatter_wprd(df)
and here are the results of the clustering:
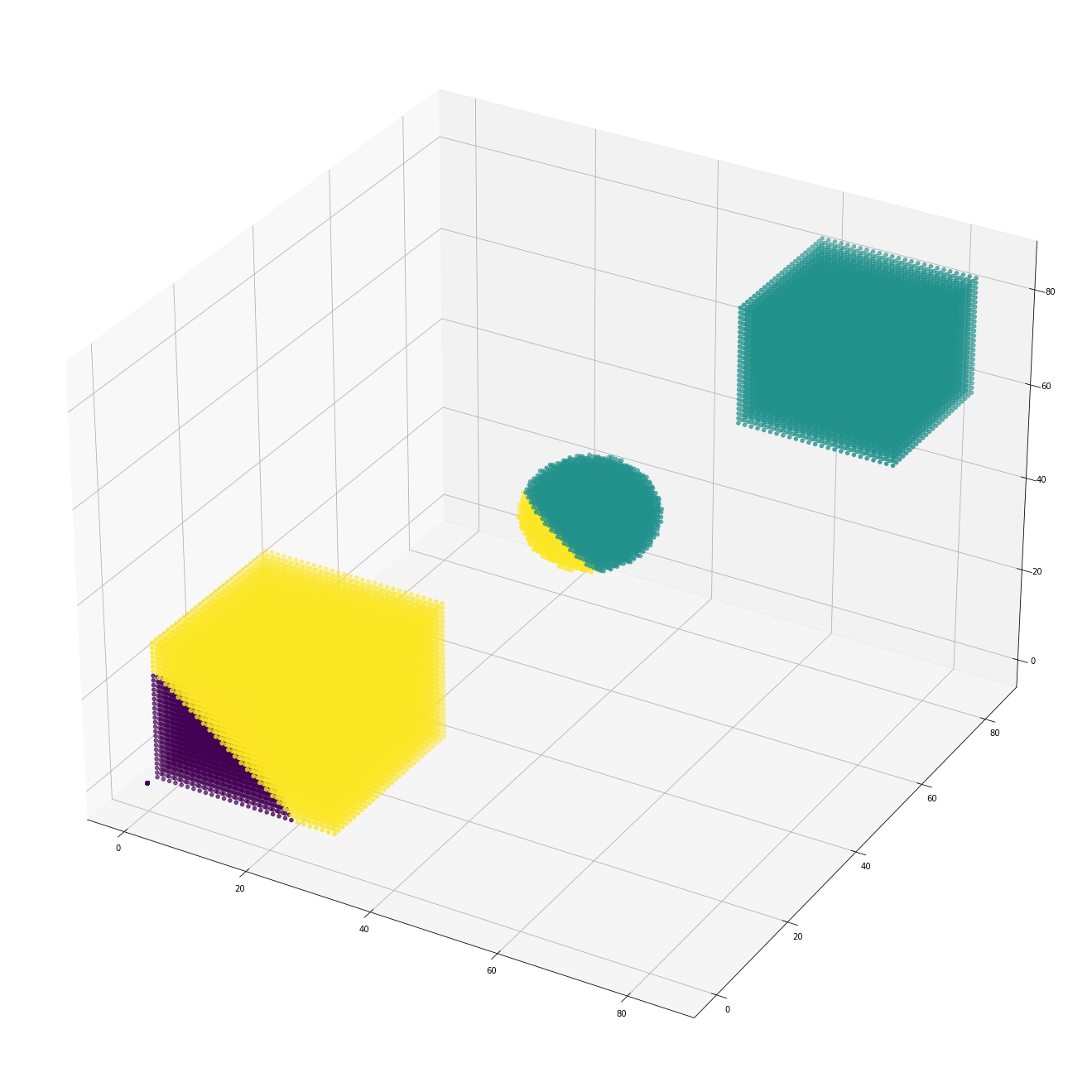
CodePudding user response:
Difficult to reproduce your problem without your data and you will understand why.
f = lambda l,h: (np.random.randint(l, h, (30,30,30)) \
np.random.random((30, 30, 30))).reshape(-1, 3)
df = pd.DataFrame(np.concatenate([f(10, 20), f(20, 30), f(30, 40)]),
columns=list('xyz'))
# Your code here
...
create_3d_scatter_wprd(df)
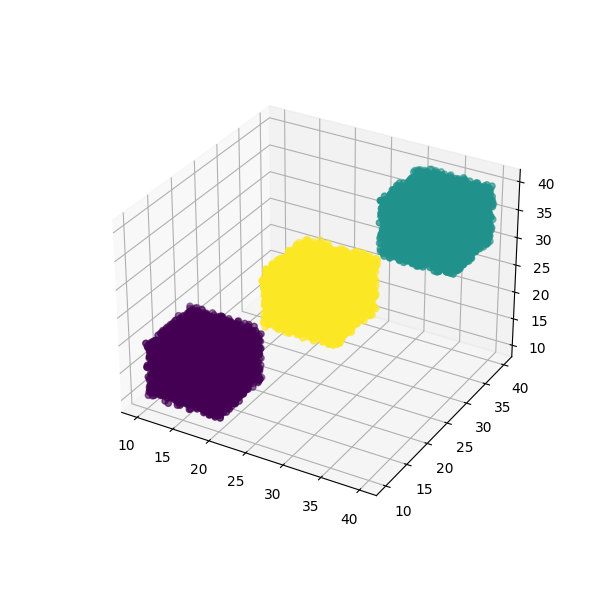
CodePudding user response:
You need to tweak the different parameters available in the KMeans. Also, you would need to do data analysis and feature engineering to develop new features if you still don't get the desired result.
https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html