Based on the output dataframe from 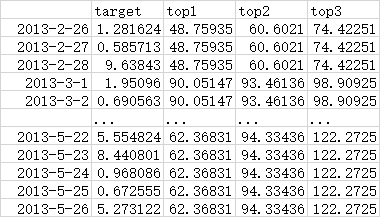
Thanks for your help at advance.
CodePudding user response:
Here's an approach with argsort:
errors = (df.groupby(pd.Grouper(freq='M'))
.apply(lambda x: mape(x[models], x[['target']]))
)
k = 2 # your k here
# filter top k models
sorted_args = np.argsort(errors, axis=1) < k
res = pd.merge_asof(df[['target']], sorted_args,
left_index=True,
right_index=True,
direction='forward'
)
topk = df[models].where(res[models])
Then topk looks like:
A_values B_values C_values D_values E_values
2013-02-26 6.059783 NaN NaN 3.126731 NaN
2013-02-27 1.789931 NaN NaN 7.843101 NaN
2013-02-28 9.623960 NaN NaN 5.612724 NaN
2013-03-01 NaN NaN 4.521452 NaN 5.693051
2013-03-02 NaN NaN 5.178144 NaN 7.322250
... ... ... ... ... ...
2013-05-22 NaN NaN 0.427136 NaN 6.803052
2013-05-23 NaN NaN 2.225667 NaN 2.756443
2013-05-24 NaN NaN 7.212742 NaN 0.430184
2013-05-25 NaN NaN 5.384490 NaN 5.461017
2013-05-26 NaN NaN 9.823048 NaN 6.312104