I have a time series with 3 sensors, one of them is a proximity switch that tells me revolutions.
Depending at what speed the machine is spinning, the distance in time of the "blips" in this sensor will change, however, regardless of how far apart these blips are, I want to divide all the data that occurred between them in 10 equally sized blocks.
I understand that the exact number of rows might not be divisible by 10 exactly but that's fine.
Timestamp Sensor_1 Sensor_2 Sensor_3
1636496284130 60.875 35.946 0
1636496284132 58.467 33.889 0
1636496284134 58.668 37.253 0
1636496284136 57.966 30.540 0
1636496284138 56.712 33.254 0
I would like to have the resulting DataFrame to have an additional Label column with what interval is taking place.
Timestamp Sensor_1 Sensor_2 Sensor_3 Label
1636496284130 60.875 35.946 0 A
1636496284132 58.467 33.889 0 A
1636496284134 58.668 37.253 0 A
1636496284136 57.966 30.540 0 A
1636496284138 56.712 33.254 0 A
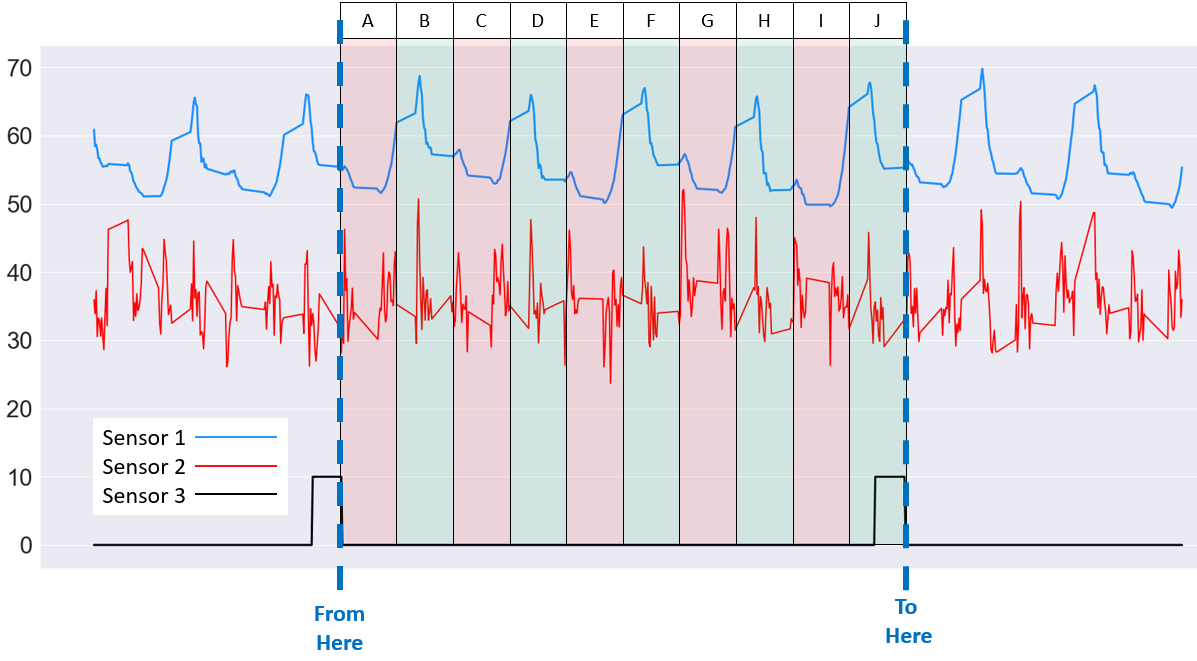
Here's a visual of what I'm trying to achieve.
CodePudding user response:
Supposing df is your input dataframe and you want to split it in n_parts (i.e. only 2 for sake of demonstration):
# Number of equally sized blocks
n_parts = 2
# Number of blocks needed to achieve that
n_blocks = df.shape[0] / n_parts
df['Label'] = ['{}'.format(i//n_blocks) for i in range(0, df.shape[0])]
# Output
Timestamp Sensor_1 Sensor_2 Sensor_3 Label
0 1636496284130 60.875 35.946 0 0.0
1 1636496284132 58.467 33.889 0 0.0
2 1636496284134 58.668 37.253 0 0.0
3 1636496284136 57.966 30.540 0 1.0
4 1636496284138 56.712 33.254 0 1.0
The // (floor operator) makes sure you get the same label if the current i is less than n_blocks:
# n_blocks is 2.5 here, therefore at i=3 we will see the value 1.0
print(['{}'.format(i//n_blocks) for i in range(0, df.shape[0])])
['0.0', '0.0', '0.0', '1.0', '1.0']
CodePudding user response:
Convert the timestamps to_datetime and cut them using bins and labels.
Here I've used 2 bins for the sample data:
df['Label'] = pd.cut(pd.to_datetime(df['Timestamp']), bins=2, labels=list('AB'))
# Timestamp Sensor_1 Sensor_2 Sensor_3 Label
# 0 1636496284130 60.875 35.946 0 A
# 1 1636496284132 58.467 33.889 0 A
# 2 1636496284134 58.668 37.253 0 A
# 3 1636496284136 57.966 30.540 0 B
# 4 1636496284138 56.712 33.254 0 B