My problem is understand the relation of primary keys to the fact table.
This is the structure I'm working in, the transfer works but it says the values I set as primary keys cannot be NULL
This is the structure I'm working in, the transfer works but it says the values I set as primary keys cannot be NULL
I'm using SSIS to transfer data from a CSV file to an OLEDB (SQL server 2019 over SSMS)
The actual problem is where/how I can get the values in the same task? I tried to do in in two different tasks but then it is in the table one after another ( this only worked when I allowed nulls for the primary keys and can't be a solution I think.)
Maybe the problem I have three transfer from the source
First dimension table
To second dimension table
To fact table. I think the primary keys are generated when I transfer the data to the DB so I think I can't get it in the same task.
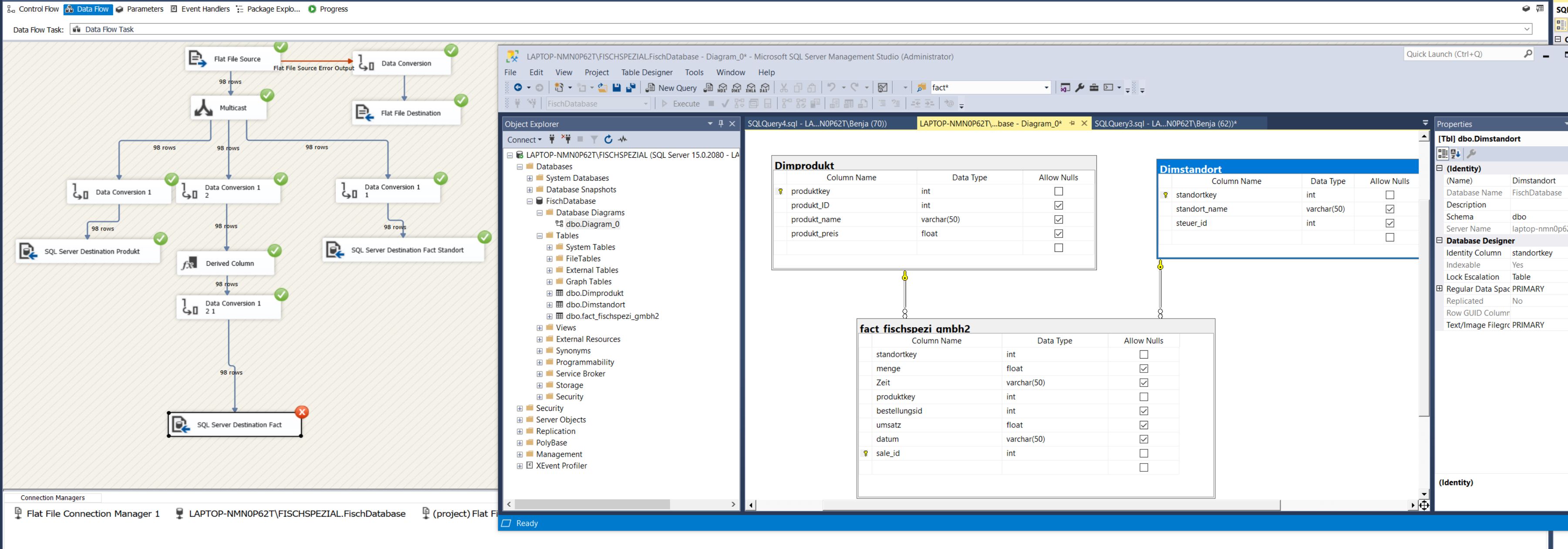
dataflow 1
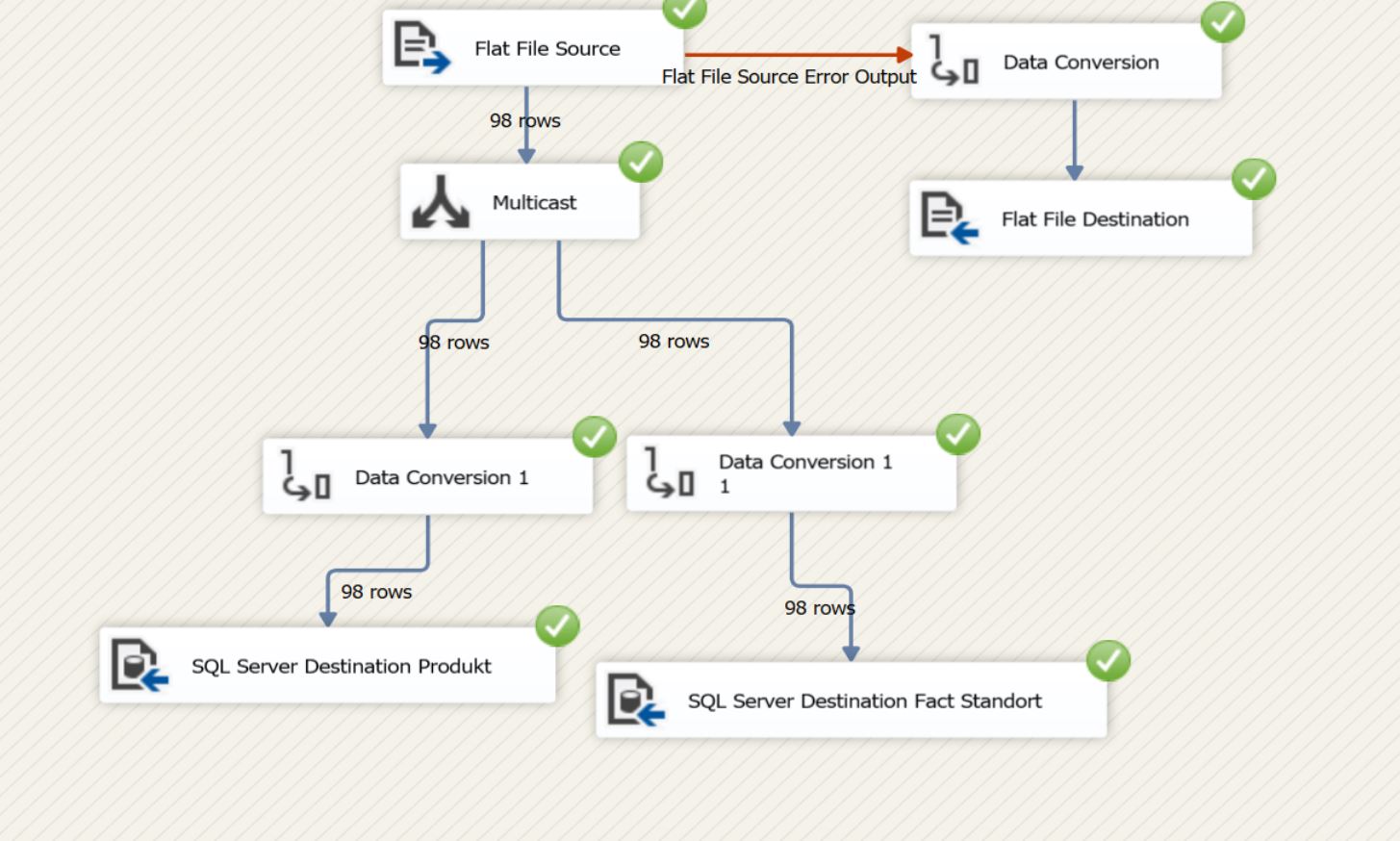
dataflow 2
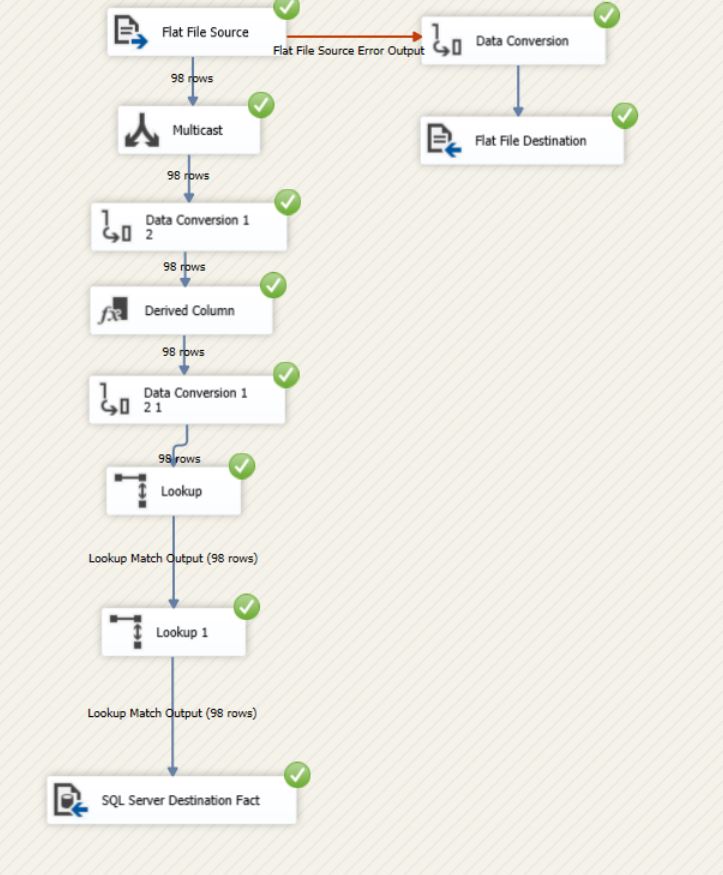
input data
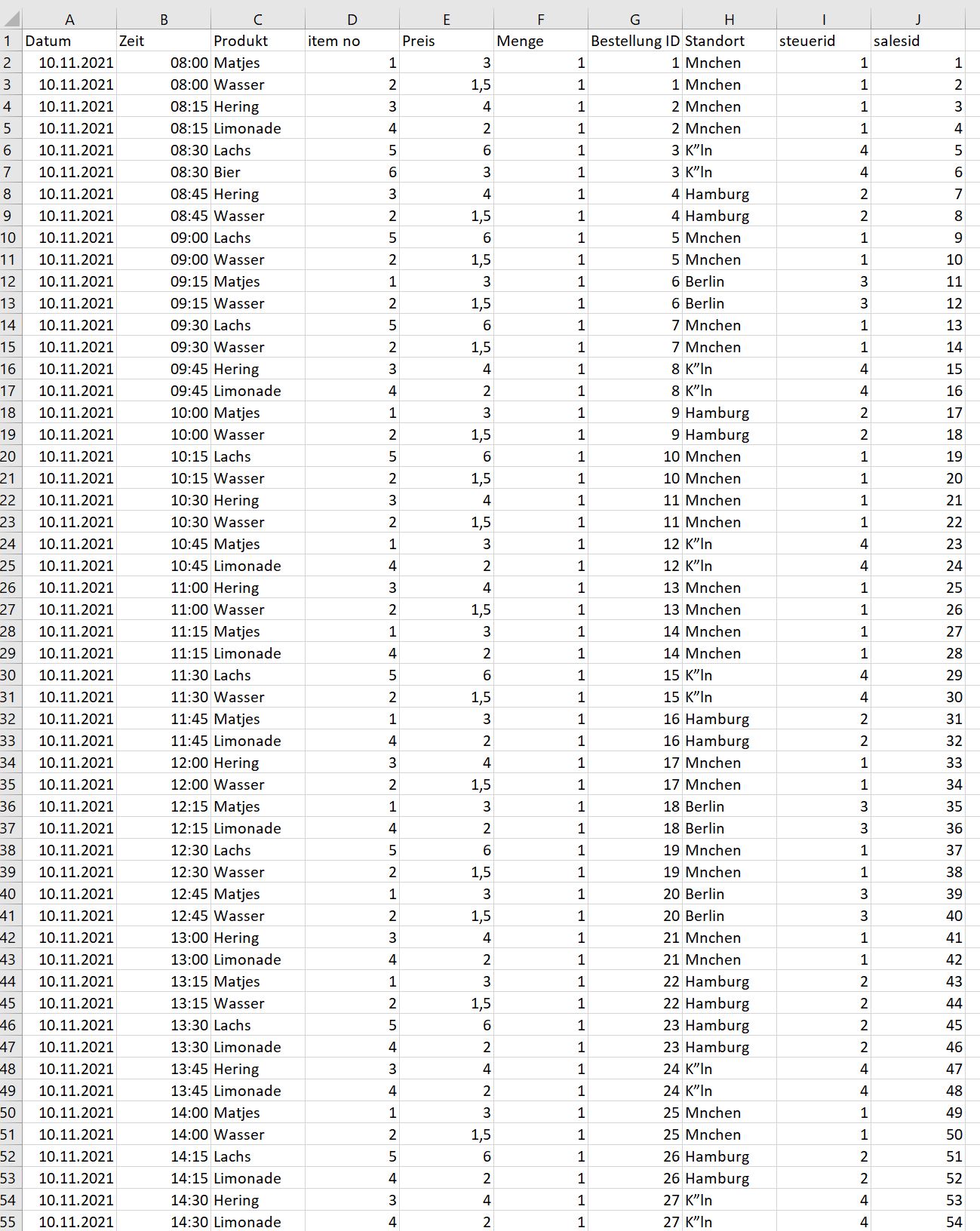
output data 5
I added the column salesid to the input to use it for the saleskey. Is there a better solution maybe with the third lookup you've mentioned?
CodePudding user response:
You are attempting to load the fischspezi fact table as well as the product (produkt) and location (standort). The problem is, you don't have the keys from the dimensions.
I assume the "key" columns in your dimension are autogenerated/identity values? If that's the case, then you need to break your single data flow into two data flows. Both will keep the Flat File source and the multicast.
Data Flow Dimensions
This is the existing data flow, minus the path that leads to the Fact table.
Data Flow Fact
This data flow will work to populate the Fact table. Remove the two branches to the dimension tables. What we need to do here, is find the translated key values given our inputs. I assume produkt_ID and steuer_id should have been defined as NOT NULL and unique in the dimensions but the concept here is that we need to be able to use a value that comes in our file, product id 3892, and find the same row in the dimension table which has a key value of 1.
The tool for this, is the Lookup Transformation You're going to want 2-3 of those in your data flow right before the destination. The first one will lookup produktkey based on produkt_ID. The second will find standortkey based on steuer_id.
The third lookup you'd want here (and add back into the dimension load) would lookup the current row in the destination table. If you ran the existing package 10 times, you'd have 10x data (unless you have unique constraints defined). Guessing here, but I assume sale_id is a value in the source data so I'd have a lookup here to ensure I don't double load a row. If sales_id is a generated value, then for consistency, I'd rename the suffix to key to be in line with the rest of your data model.
I also encourage everyone to read Andy Leonard's Stairway to Integration Services series. Levels 3 &4 address using lookups and identifying how to update existing rows, which I assume will be some of the next steps in your journey.
Addressing comments
I would place them just over the fact destination and then join with a union all to fact table
No. There is no need to have either a join or a union all in your fact data flow. Flat File Source (Get our candidate data) -> Data Conversion(s) (Change data types to match the expected)-> Derived Columns (Manipulate the data as needed, add things like insert date, etc) -> Lookups (Translate source values to destination values) -> Destination (Store new data).
Assume Source looks like
| produkt_ID | steuer_id | sales_id | umsatz |
|---|---|---|---|
| 1234 | 1357 | 2468 | 12 |
| 2345 | 3579 | 4680 | 44 |
After dimension load, you'd have (simplified)
Product
| produktkey | produkt_ID |
|---|---|
| 1 | 1234 |
| 2 | 2345 |
Location
| standortkey | steuer_id |
|---|---|
| 7 | 1357 |
| 9 | 3579 |
The goal is to use that original data lookups to have a set like
| produkt_ID | steuer_id | sales_id | umsatz | produktkey | standortkey |
|---|---|---|---|---|---|
| 1234 | 1357 | 2468 | 12 | 1 | 7 |
| 2345 | 3579 | 4680 | 44 | 2 | 9 |
The third lookup I propose (skip it for now) is to check whether sales_id exists in the destination. If it does, then you would want to see whether that existing record is the same as what we have in the file. If it's the same, then we do nothing. Otherwise, we likely want to update the existing row because we have new information - someone miskeyed the quantity and instead our sales should 120 and not 12. The update is beyond the scope of this question but it's covered nicely in the Stairway to Integration Services.