I have a parent table Orders and a Child table Jobs with the following sample data
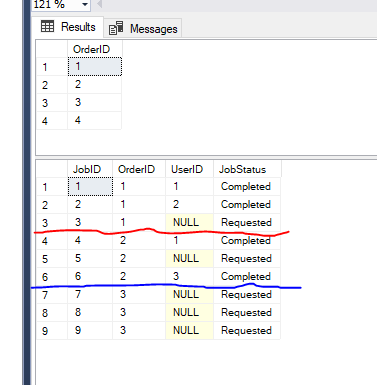
I want to select Orders based on the following requirements
1>For each order there may be 0 or more jobs. Do not select order if it does not have any job.
2>A user cannot work on more than one job that belongs to the same order.
For example User 1 cannot work on the Jobs that belongs to Order 1 and 2 because he already worked on jobs 1 and 4 from the same order.
3>Only select orders that have jobs in Requested status
I have the following query that gives me expected result
DECLARE @UserID INT = 2
SELECT O.OrderID
FROM Orders O
JOIN Jobs J ON J.OrderID = O.OrderID
WHERE
J.JobStatus = 'Requested' AND
NOT EXISTS
(
--Must not have worked this Order
SELECT 1 FROM Jobs J1
WHERE J1.OrderID = O.OrderID AND J1.UserID = @UserID
)
Group By o.OrderID
Query joins the Jobs table twice. I am trying to optimize query and looking for a way to achieve the expected result by using Jobs table only once if possible. Any other solution is also appreciated. I can alter the table schema if required.
The jobs table has almost 20M rows and some time query shows poor performance. (Yes, we looked at indexes). I think its scanning jobs table twice causing the performance issue.
CodePudding user response:
You might consider adding the following index to the Jobs table:
CREATE INDEX idx_jobs ON Jobs (OrderID, UserID, JobStatus);
This index, if used, should speed up the not exists subquery in your query above. Also, it can be used for the join from Orders to Jobs in the outer top level query (although SQL Server would probably have to do an index scan).
CodePudding user response:
If the aim is just to "use Jobs table only once", I would try something like:
DECLARE @UserID INT = 2
SELECT
O.OrderID
FROM
Orders O
INNER JOIN Jobs J ON J.OrderID = O.OrderID
GROUP BY
O.OrderID
HAVING
SUM(CASE WHEN J.JobStatus = 'Requested' THEN 1 ELSE 0 END) > 0
AND SUM(CASE WHEN J.UserID = @UserId THEN 1 ELSE 0 END) = 0
To optimize further, I would suggest replacing the varchar datatype of the JobStatus column with tinyint one (and create a JobStatuses table). Once your Job table has 20M records, then varchar(10) gives you 190 Mb, however using the tinyint reduces the column size to 19 Mb — this gives you less IO-Read operations.
And I would try to separate the child filtering from joining it with the parents. Such approach may use less memory for a single operation and win in performance because of that:
DECLARE @UserID INT = 2
DECLARE @OrderIDs TABLE (OrderID INT NOT NULL PRIMARY KEY)
INSERT INTO @OrderIDs
SELECT
OrderID
FROM
Jobs
GROUP BY
OrderID
HAVING
SUM(CASE WHEN JobStatus = 'Requested' THEN 1 ELSE 0 END) > 0
AND SUM(CASE WHEN UserID = @UserId THEN 1 ELSE 0 END) = 0
SELECT
O.*
FROM
Orders O
INNER JOIN @OrderIDs ids on ids.OrderID = O.OrderID