I use VS Code to write 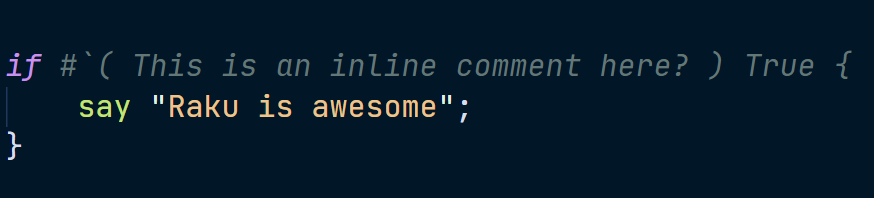
In Raku,
embedded comment is
if #`( This is an inline comment here? ) True {
say "Raku is awesome";
}
multi-line comment is
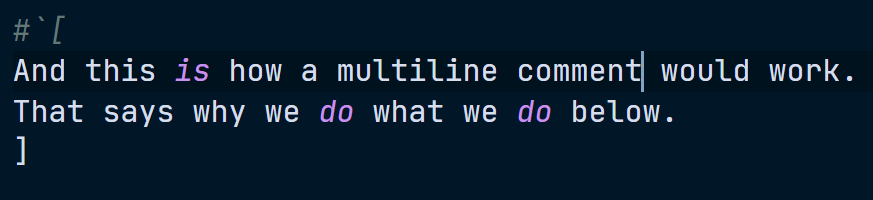
#`[
And this is how a multiline comment would work.
That says why we do what we do below.
]
say "Raku is awesome";
pod comment is
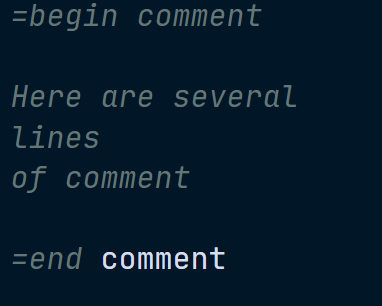
=begin comment
Here are several
lines
of comment
=end comment
say "Hello";
The problem is once VS code sees #, it comments out the whole line which should not be the case in embedded comments.
Further details here.
To understand, I saw the source configuration file for Raku https://github.com/microsoft/vscode/blob/main/extensions/perl/perl6.language-configuration.json (not updated for ~ 2yrs !). Tried some modifications
"comments": {
// symbol used for single line comment. Remove this entry if your language does not support line comments
"lineComment": "#",
// symbols used for start and end a block comment. Remove this entry if your language does not support block comments
"blockComment": [
[ "/*", "*/" ],
["#`(", ")"],
["#`[", "]"],
["#`{", "}"],
["#`<", ">"],
["=begin", "=end"]
]
but doesn't seem to work.
How do I make it work the right way?
CodePudding user response:
TL;DR If we're really lucky I've solved your problems. More likely I've just provided food for thought.
My best shot at solving the problems in your Q
First, let me try tackle/discuss the specific two problems you've written about.
// symbol used for single line comment.
"lineComment": "#",
Having browsed the VS Code doc my preliminary guess is that the string "#" is a regex in the dialect supported by the Textmate grammars mentioned in the VS Code doc. That suggests, if one uses the PCRE regex dialect:
// symbol used for single line comment.
"lineComment": "#(?!`[(\[{<])"
The point here is to ensure the "symbol" regex (presuming it is a regex) does not match code starting with #`( or the other variants you allow for in your block comment configuration.
Moving on:
// symbols used for start and end a block comment.
"blockComment": [
[ "/*", "*/" ],
["#`(", ")"],
["#`[", "]"],
["#`{", "}"],
["#`<", ">"],
["=begin", "=end"]
]
First off, I presume the [ "/*", "*/" ], line should be deleted. Raku doesn't support that form of block commenting.
Next, having browsed the Textmate page linked above it seems like this might work for the last bit for use of =begin foo:
["^=begin\s (\w )", "\n=end\s \1"]
The point here is to:
Capture the comment identifier that comes after the
=begin. (I've used the syntax(...)because that's the most common syntax among regex dialects for a capture, just like it works in Raku regexes.) The pattern I've written is just\wwhich will only match simple identifiers but it's a start, presuming, as noted before, that these VS Code "symbol" strings are indeed regexes.Insert whatever was captured after the
=end. (\1is the most common syntax, among regex dialects, for inserting the first numbered capture. This corresponds to the syntax$0that would be used in Raku regexes.)
I've also added:
A
^before the=beginto limit matching to when it's at the start of a line. But perhaps that ought be removed for this regex to work with VS Code.A
\nbefore the=endfor the same reason. (But my guess is that^is the right thing for=beginwhereas\nis right for=end.)
The next best shot
If those changes do not work, and even if they do, then maybe try fiddling with them, and/or experiment with a regex test tool (eg regex101.com), and/or read up on the regex dialect supported by the Textmate technology (there are links in the VS Code doc; I read some of Language Grammars in preparing the above suggestions).
I must say I was struggling to understand the Textmate doc (understatement!). So if the above doesn't work, and you can't figure it out either, then maybe we should add a [textmate] tag to your Q to try catch the attention of SO folk who know this regex dialect / aspect of VS Code.
Even if you fix these two problems, at least for simple cases, there will be many others. Raku has a complex grammar!
The rest of this answer covers the bigger picture, not specific to solving these particular problems with the syntax highlighter but instead the overall problem of making a tool highlight Raku code correctly, performantly, and maintainably.
The bigger picture
How do I make it work the right way?
If it were me I'd look at what has been achieved for syntax highlighting in other tools. Can any of those correctly highlight your examples? If so, how do they manage that? What regex dialects do they use and what regex patterns?
Specifically:
Does CommaIDE deal with your examples? If it does, then regardless of whether it uses approach 1 or 2, it might make sense to use the same approach with VS Code, or a similar one, if you can.
What about emacs or vi? If either of those work, what regex dialects/engines do they use, and can you use the same regexes in VS Code?
Two approaches
It's worth being clear about the following two different approaches to doing this sort of thing, regardless of whether the editor / IDE being customized is VS code or any other:
Create a Raku grammar and actions class, and plug Rakudo and this grammar into the tool.
Create (non-Raku) regexes in some regex engine and plug those into the tool.
There are different challenges depending on which of these approaches is used:
Raku has a challenging grammar.
We know a Raku grammar can be written that will parse it with perfect fidelity -- because that's exactly how Rakudo parses Raku code. If a tool will allow that grammar and Rakudo to be plugged into that tool then that's going to be the "easiest" solution -- except it's only going to be a solution if one overcomes the next challenge, which is that even if a tool does support plugging Rakudo in -- the most appropriate standard approach is LSP[1] -- you'll hit the problem of performance:
1.1 Rakudo is slow in general, and especially its grammar engine.
1.2 There's a need (at least in principle) for features such as syntax highlighting to reprocess all the code being edited each time a character is inserted or deleted in order to know how to parse it.
Many PL's grammars/compilers are such that this is tractable with acceptable performance. Some modern parsing technologies and/or compilers specifically focus on incremental parsing that radically speeds up reprocessing code with small changes of code between parses of it.
With Raku(do) as it stands (and quite plausibly for the rest of this decade at least) this is a big problem. Things might significantly change if/when the grammar engine is rewritten, which I think might happen in the 2023-2025 timeframe, but in the meantime it's more than somewhat plausible that Rakudo can't parse fast enough to be a syntax highlighting solution using LSP or similar.
(This is why CommaIDE does not use Rakudo for syntax highlighting but instead uses a separate parser that's much faster / more incremental.)
Which leads to the second approach, the one you are currently trying to work with:
The main other approach used to syntax highlight code in tools is to write regexes in some non-Raku regex dialect that's supported by a given editor or other tool for this purpose. This approach introduces its own set of challenges:
2.1 Does the tool interface with the regexes in such a way that they have an opportunity of matching elements that are to be highlighted?
2.2 If this opportunity exists, is a given regex dialect that a tool supports blessed with sufficient power to do the matching correctly?
2.3 If a dialect has enough power, can that power be wielded by someone with sufficient skill and determination by someone that highlighting will be sufficiently complete and fast? There's no point in writing a highlighter that routinely noticeably slows typing down.
2.4 If VS Code provides sufficient opportunity for hooking in regexes, and the regex dialect has sufficient power, and sufficient skill and determination is applied, and then maintained, then that's going to be great news.
The two approaches in VS Code
Interspersing quotes from the Syntax Highlight Guide with my commentary:
VS Code's tokenization engine is powered by TextMate grammars. TextMate grammars are a structured collection of regular expressions...
So this is solution 2 from the above list -- "write regexes in some non-Raku regex dialect". And that leads to the sub-problems I listed.
VS Code also allows extensions to provide tokenization through a Semantic Token Provider.
This sounds like it might be the first approach, making use of Rakudo in a Raku specific language server. I think there's little chance this can be made even close to fast enough for basic syntax highlighting, at least in the near term, but maybe I'm wrong.
Semantic providers are typically implemented by language servers that have a deeper understanding of the source file ... Semantic highlighting goes on top of the syntax highlighting. And as language servers can take a while to load and analyze a project, semantic token highlighting may appear after a short delay.
Two issues of note:
They're saying their design is such that this approach "goes on top of" approach 2, with a delay. So, again, even if Rakudo was fast, it seems this approach is not intended for basic highlighting for most PLs.
They characterize the delay as "short". This is clearly intended to be somewhat vague -- allowing for PLs with fast/incremental parsers, but also ones without them -- but I suspect they ain't reckoning with just how slow Raku(do) parsing can be, especially of Raku code!
Footnotes
[1] LSP = Language Server Protocol.