I have a data table that includes 4 columns: "file", "date", "name", and "rt". There are 25 different names, which apply to hundreds of observations. I want to rearrange the data table so that the unique names are column headers, with multiple rt values corresponding to dates. There may be more than one observation of each name on any given date.
So there should only be one row for each "file", (there are currently 25), instead of the "name" column, I want a column for each unique name. I also want to be able to do this rearranging programmatically because there will be other scenarios where there is a different list of names. But for this current scenario, the idea is to have one row per file, with columns labelled 'file', 'date', name 1, name 2, etc., and then have the rt data populate the table.
Input data looks like this:
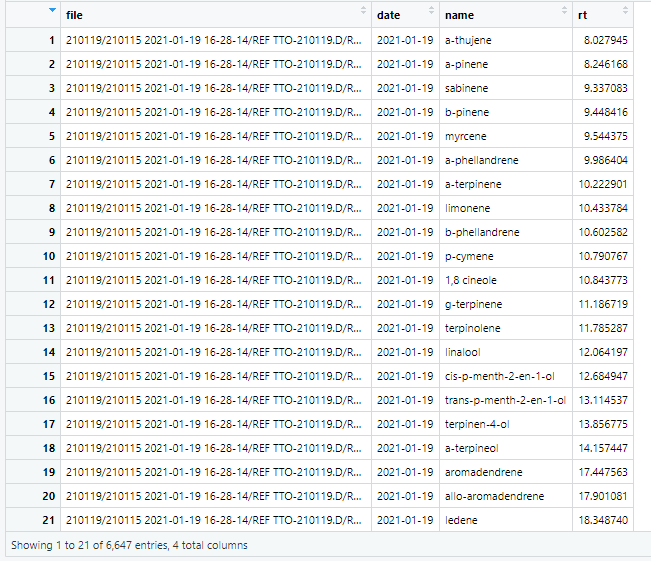
The output should be arranged something like this:
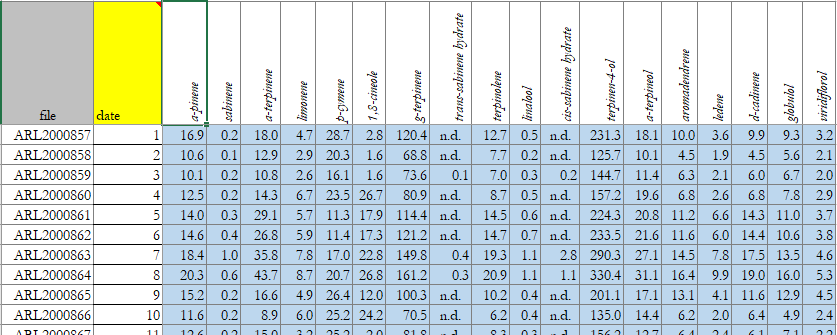
CodePudding user response:
pivot_wider should work: https://tidyr.tidyverse.org/reference/pivot_wider.html
library(tidyr)
df %>% pivot_wider(names_from = name, values_from = rt)
CodePudding user response:
Use:
colnames(file)[5:29]<- unique(file$name)