I'm very new to R (and statistics) and I searched a lot for a possible solution, but couldn't find any.
I have a data set with around 18000 entries, which contain two columns: "rentals" and "season". I want to analyse if there is a difference between the mean of the rentals depending on the season using an one-way ANOVA.
My data looks like this:
| rentals | season |
|---|---|
| 23 | 1 |
| 12 | 1 |
| 17 | 2 |
| 16 | 2 |
| 44 | 3 |
| 22 | 3 |
| 2 | 4 |
| 14 | 4 |
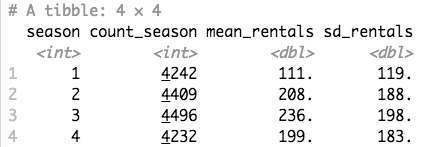
First I calculate the SD and MEAN of the groups (season):
anova %>%
group_by(season) %>%
summarise(
count_season = n(),
mean_rentals = mean(rentals, na.rm = TRUE),
sd_rentals = sd(rentals, na.rm = TRUE))
This is the result:
Then I perform the one-way ANOVA:
anova_one_way <- aov(season~as.factor(rentals), data = anova)
summary(anova_one_way)
<!-- I use "as.factor" on rentals, because otherwise I'm getting an error with TukeyHSD -->
Result:

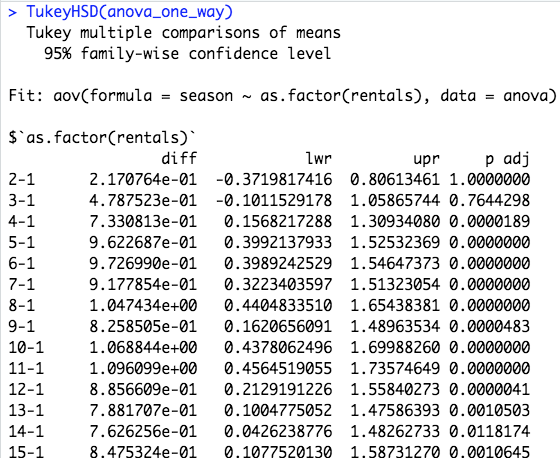
Here comes the tricky part. I perform a TukeyHSD test:
TukeyHSD(anova_one_way)
And the results are very disappointing. TukeyHSD returns 376896 rows, while I expect it to return just a few, comparing the seasons with each other. It looks like every single "rentals" row is being handled as a single group. This seems to be very wrong but I can't find the cause. Is this a common TukeyHSD behaviour considering the big data set or is there an error in my code or logic, which causes this enormous unreadable list of values as a return?
Here is a small insight on how it looks like (and it goes on until 376896).
CodePudding user response:
The terms are the wrong way around in your aov() call. Rentals is the outcome (dependent) variable, season is the predictor (independent) variable.
So you want:
anova_one_way <- aov(rentals ~ factor(season), data = anova)