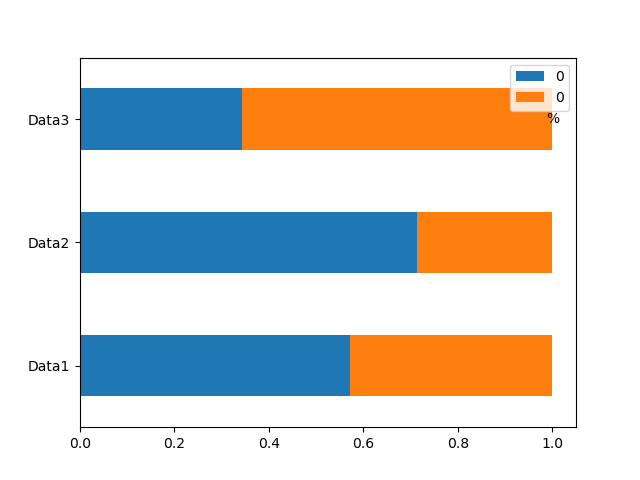
I have a list of 0,1 in dataframe. How can I plot a percentage of bar plot in pandas or matplotlib, that would have in the legend 1,0 and written annotation of percentage of the 1,0 compare to the whole list?
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
list_1 = [1,0,1,1,1,0,0,1,0,1,1,1,0,0,1,0,1,1,1,0,0,1,0,1,1,1,0,0,1,0,1,1,1,0,0,]
list_2 = [1,1,1,1,1,0,0,1,1,1,1,1,0,0,1,0,1,1,1,0,1,1,0,1,1,1,0,1,1,0,1,1,1,1,0,]
list_3 = [1,0,1,1,1,0,0,0,0,1,1,1,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,1,0,1,1,1,0,0,]
df1 = pd.DataFrame({'Data1': list_1,'Data2': list_2,'Data3': list_3})
df1 = df1.mean()
df1.columns = ['1']
df2 = pd.DataFrame(1-df1)
df2.columns = ['0']
df1 = pd.DataFrame(df1)
df = pd.concat([df1,df2], axis=1)
df.plot( kind='barh',stacked = True,mark_right = True) # this is ok
plt.text(1,2,'%', va = 'center', ha = 'center')
plt.show()
I get this plot:
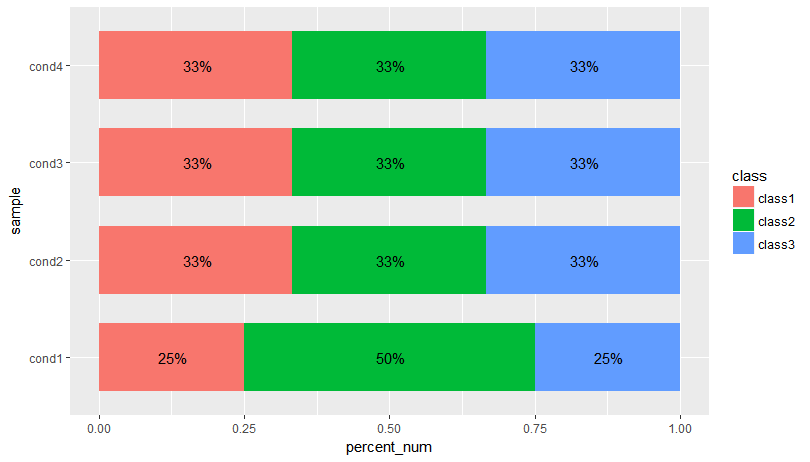
However I would get percentage of 1 and 0 for 3 lists, so something like this:
CodePudding user response:
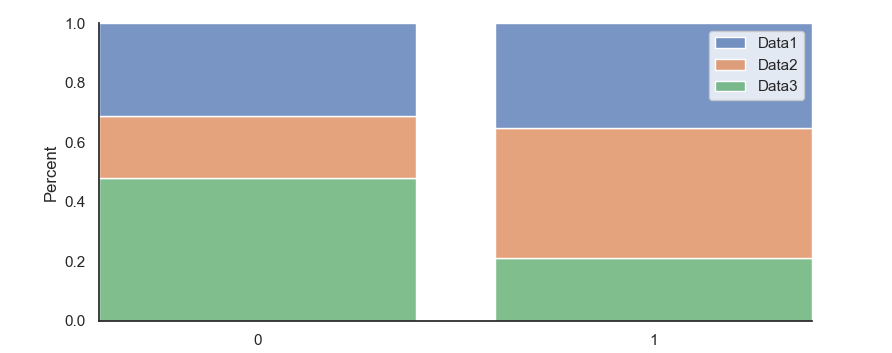
You can use seaborn's histplot with multiple='fill'
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
list_1 = [1,0,1,1,1,0,0,1,0,1,1,1,0,0,1,0,1,1,1,0,0,1,0,1,1,1,0,0,1,0,1,1,1,0,0]
list_2 = [1,1,1,1,1,0,0,1,1,1,1,1,0,0,1,0,1,1,1,0,1,1,0,1,1,1,0,1,1,0,1,1,1,1,0]
list_3 = [1,0,1,1,1,0,0,0,0,1,1,1,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,1,0,1,1,1,0,0]
df = pd.DataFrame({'Data1': list_1, 'Data2': list_2, 'Data3': list_3})
sns.set(style='white')
ax = sns.histplot(data=df, stat='percent', multiple='fill', discrete=True, shrink=0.8)
sns.despine()
ax.set_xticks([0, 1])
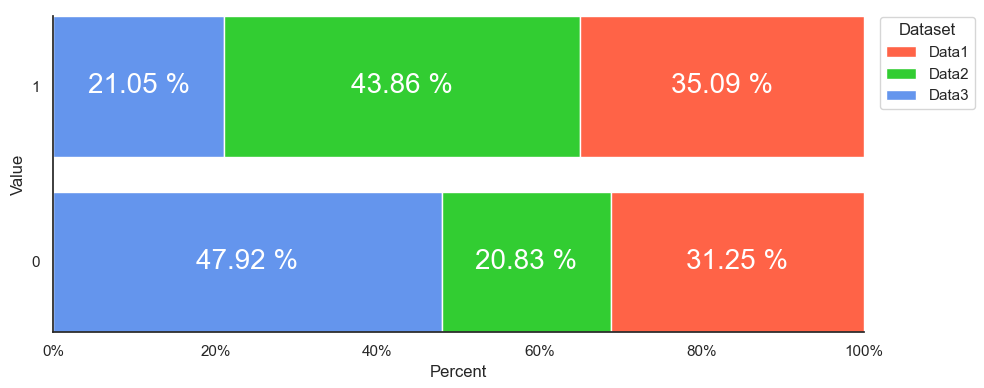
For horizontal bars and further customization, it helps to convert the dataframe to long format.
import matplotlib.pyplot as plt
from matplotlib.ticker import PercentFormatter
import seaborn as sns
import pandas as pd
list_1 = [1,0,1,1,1,0,0,1,0,1,1,1,0,0,1,0,1,1,1,0,0,1,0,1,1,1,0,0,1,0,1,1,1,0,0]
list_2 = [1,1,1,1,1,0,0,1,1,1,1,1,0,0,1,0,1,1,1,0,1,1,0,1,1,1,0,1,1,0,1,1,1,1,0]
list_3 = [1,0,1,1,1,0,0,0,0,1,1,1,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,1,0,1,1,1,0,0]
df = pd.DataFrame({'Data1': list_1, 'Data2': list_2, 'Data3': list_3})
sns.set(style='white')
fig, ax = plt.subplots(figsize=(10, 4))
sns.histplot(data=df.melt(var_name='Dataset', value_name='Value'), y='Value', hue='Dataset',
stat='percent', multiple='fill', discrete=True, shrink=0.8,
palette=['tomato', 'limegreen', 'cornflowerblue'], alpha=1, ax=ax)
sns.despine()
sns.move_legend(ax, bbox_to_anchor=(1.01, 1.02), loc='upper left')
ax.set_yticks([0, 1])
ax.xaxis.set_major_formatter(PercentFormatter(1))
for p in ax.patches:
h, w, x, y = p.get_height(), p.get_width(), p.get_x(), p.get_y()
text = f'{w * 100:0.2f} %'
ax.annotate(text=text, xy=(x w / 2, y h / 2), ha='center', va='center', color='white', size=20)
plt.tight_layout()
plt.show()