It's the first time I post here and it is a tricky question, basically I have this table in which I have a patient that has taken a certain medication, but there are certain dates that are missing because the patient can buy several boxes at a time, so I basically duplicated the rows based on the number of boxes the patient bought. This leads me to this table:
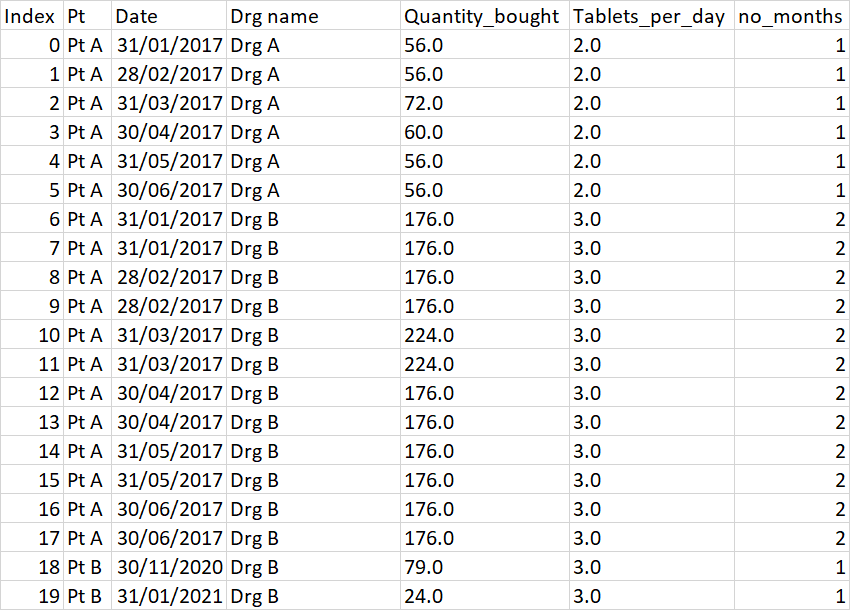
You can see that the duplicated rows all bought enough medication for two months, in this case.
What I need to do is transform the dates in a way that they are in sequence, but I can only o this when the dates are duplicated so I don't change the original data of other patients.
I have tried a for loop like this
for index,row in output_table_1.iterrows():
if index == 0:
next
elif output_table_1.loc[index, 'Date'] == output_table_1.loc[index-1, 'Date']:
output_table_1.at[index, 'Date'] = row['Date'] pd.Timedelta(days=28)
else:
output_table_1.at[index, 'Date'] = row['Date']
But it does not give me what I need, basically I need it to change the data based on previous information like this:
Original data:
| Date | |
|---|---|
| 6 | 2017-01-31 |
| 7 | 2017-01-31 |
| 8 | 2017-02-28 |
| 9 | 2017-02-28 |
| 10 | 2017-03-31 |
| 11 | 2017-03-31 |
| 12 | 2017-04-30 |
| 13 | 2017-04-30 |
First loop:
| Date | |
|---|---|
| 6 | 2017-01-31 |
| 7 | 2017-02-31 |
| 8 | 2017-02-28 |
| 9 | 2017-02-28 |
| 10 | 2017-03-31 |
| 11 | 2017-03-31 |
| 12 | 2017-04-30 |
| 13 | 2017-04-30 |
Second loop:
| Date | |
|---|---|
| 6 | 2017-01-31 |
| 7 | 2017-02-31 |
| 8 | 2017-03-28 |
| 9 | 2017-02-28 |
| 10 | 2017-03-31 |
| 11 | 2017-03-31 |
| 12 | 2017-04-30 |
| 13 | 2017-04-30 |
Third loop:
| Date | |
|---|---|
| 6 | 2017-01-31 |
| 7 | 2017-02-31 |
| 8 | 2017-03-28 |
| 9 | 2017-04-28 |
| 10 | 2017-03-31 |
| 11 | 2017-03-31 |
| 12 | 2017-04-30 |
| 13 | 2017-04-30 |
Final Output:
| Date | |
|---|---|
| 6 | 2017-01-31 |
| 7 | 2017-02-31 |
| 8 | 2017-03-28 |
| 9 | 2017-04-28 |
| 10 | 2017-05-31 |
| 11 | 2017-06-31 |
| 12 | 2017-07-30 |
| 13 | 2017-08-30 |
And so on.
CodePudding user response:
If you are still looking for a solution, you could try the following:
def adjust(ser):
if (ser == ser.shift()).any():
one_month = pd.offsets.MonthEnd()
last_month = ser.iat[0]
for i, month in ser.iloc[1:].items():
if month <= last_month:
ser.at[i] = last_month one_month
last_month = ser.at[i]
return ser
df.Date = df.groupby(["Pt", "Drg name"]).Date.transform(adjust)
Assumptions:
- All of your dates are month end dates (looks like it in the sample).
- Your example is not representative, in the sense that there could be "gaps" in the multiple date series: See the last group in my example below. If that's not nescesarry, then there's a simpler solution.
I've added the condition if (ser == ser.shift()).any() to avoid unnecessary work. If you have to adjust the majority of the groups then it's probably better to remove it.
Result for
df =
Pt Date Drg name
0 Pt A 2017-01-31 Drg A
1 Pt A 2017-02-28 Drg A
2 Pt A 2017-03-31 Drg A
3 Pt A 2017-04-30 Drg A
4 Pt A 2017-05-31 Drg A
5 Pt A 2017-06-30 Drg A
6 Pt A 2017-01-31 Drg B
7 Pt A 2017-01-31 Drg B
8 Pt A 2017-02-28 Drg B
9 Pt A 2017-02-28 Drg B
10 Pt A 2017-03-31 Drg B
11 Pt A 2017-03-31 Drg B
12 Pt A 2017-04-30 Drg B
13 Pt A 2017-04-30 Drg B
14 Pt B 2020-11-30 Drg B
15 Pt B 2020-11-30 Drg B
16 Pt B 2021-02-28 Drg B
17 Pt B 2021-02-28 Drg B
is
Pt Date Drg name
0 Pt A 2017-01-31 Drg A
1 Pt A 2017-02-28 Drg A
2 Pt A 2017-03-31 Drg A
3 Pt A 2017-04-30 Drg A
4 Pt A 2017-05-31 Drg A
5 Pt A 2017-06-30 Drg A
6 Pt A 2017-01-31 Drg B
7 Pt A 2017-02-28 Drg B
8 Pt A 2017-03-31 Drg B
9 Pt A 2017-04-30 Drg B
10 Pt A 2017-05-31 Drg B
11 Pt A 2017-06-30 Drg B
12 Pt A 2017-07-31 Drg B
13 Pt A 2017-08-31 Drg B
14 Pt B 2020-11-30 Drg B
15 Pt B 2020-12-31 Drg B
16 Pt B 2021-02-28 Drg B
17 Pt B 2021-03-31 Drg B