I have a sql table like below
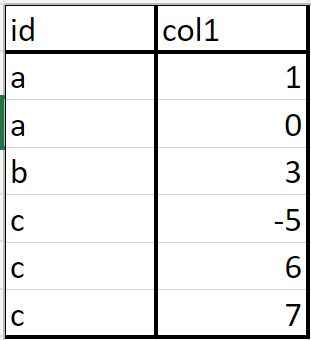
So the id column contains the unique elements a, b, and c. I would like to choose at random (uniformly) 2 out of a, b, and c and then take all rows whose id is either one of these 2 elements. For example, if a and b are chosen. Then my desired result is

I have read this thread, but it is about subsample uniformly on the set of all rows. On the other hand, my subsample is extracted from the set of unique elements of a column
idand then take all rows whoseidbelongs to this subsample.My work is on Sagemaker of AWS, so I can extract the whole dataframe and perform subsample and extraction by Python. However, I guess this is slower than performing subsample directly by sql.
Could you elaborate on how to efficiently subsample in this case?
CodePudding user response:
in MS SQL Server you can use next trick:
SELECT * FROM t WHERE id in (
-- select 2 random id
SELECT top 2 MIN(id) id FROM t GROUP by id ORDER BY NEWID()
);
I mean this query can be easy adopted to other RDBMS versions
CodePudding user response:
You can use this :
SELECT ID, Col1
FROM my_table
WHERE rownum = round(rand() * 999) 1
rand() returns a value between 0 and 1 so you need to multiply to a factor that gives a large enough range. Round it and ad 1 to have an integer and 1 as lowest value.