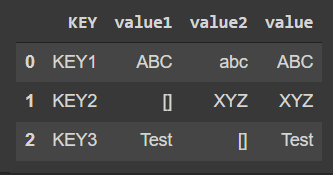
Hey I have two DataFrames: data1 with columns KEY, value1, value2, and data2 with column KEY(but we can assume that there is much more columns). Now I want to create value column in data1 in such a way that if a given key is in KEY column in data2, then value is equal to value2, and else it is equal to value1. Here is my code:
import pandas as pd
d1 = {"KEY": ["KEY1", "KEY2", "KEY3"], "value1": ["ABC",[] , []], "value2": ["abc", "XYZ",[] ]}
data1 = pd.DataFrame(d1)
d2 = {"KEY": ["KEY2"]}
data2 = pd.DataFrame(d2)
data1["value"] = data1.apply(lambda x: x["value2"] if x["KEY"] in list(data2["KEY"]) else x["value1"], axis = 1)
It works properly but I would like to know if it is the most efficient method or I can do that better.
CodePudding user response:
I think this code will be more efficient because there is no going over each row one by one using apply.
Here is the code:
import pandas as pd
d1 = {"KEY": ["KEY1", "KEY2", "KEY3"], "value1": ["ABC",[] , []], "value2": ["abc", "XYZ",[] ]}
data1 = pd.DataFrame(d1)
d2 = {"KEY": ["KEY2"]}
data2 = pd.DataFrame(d2)
index_1 = data1.set_index("KEY").index
index_2 = data2.set_index("KEY").index
intersection = index_1.isin(index_2)
data1.loc[intersection, "value"] = data1.loc[intersection, "value2"]
data1.loc[~intersection, "value"] = data1.loc[~intersection, "value1"]
And output: