I have a column like this:
| String_to_Extract |
|---|
| A~S1_B~S2_C~S11 |
| A~S1_B~S3_C~S12 |
| C~S13_A~S11_B~S4 |
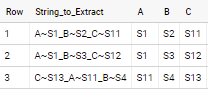
The part before the "~" should be the column name. The part after the "~" should be the row value. This is separated by a "_" . Therefore, the result should look like this:
| String_to_Extract | A | B | C |
|---|---|---|---|
| A~S1_B~S2_C~S11 | S1 | S2 | S11 |
| A~S1_B~S3_C~S12 | S1 | S3 | S12 |
| C~S13_A~S11_B~S4 | S11 | S4 | S13 |
Here is my approach:
SELECT
String_to_Extract,
SUBSTRING(String_to_Extract, INSTR(Advertiser, "A~") 2, ?) AS A,
SUBSTRING(String_to_Extract, INSTR(Advertiser, "B~") 2, ?) AS B,
SUBSTRING(String_to_Extract, INSTR(Advertiser, "C~") 2, ?) AS C,
From Table
How do I get the part between the ~ and next _ for each column?
Would be glad about help!
CodePudding user response:
One approach uses REGEXP_EXTRACT:
SELECT
REGEXP_EXTRACT(String_to_Extract, r"(?:^|_)A~([^_] )") AS A,
REGEXP_EXTRACT(String_to_Extract, r"(?:^|_)B~([^_] )") AS B,
REGEXP_EXTRACT(String_to_Extract, r"(?:^|_)C~([^~] )") AS C
FROM yourTable;
CodePudding user response:
Consider below approach (BigQuery)
select * from (
select String_to_Extract, col_val[offset(0)] as col, col_val[offset(1)] as val
from your_table, unnest(split(String_to_Extract, '_')) kv,
unnest([struct(split(kv, '~') as col_val)])
)
pivot (any_value(val) for col in ('A', 'B', 'C'))
If applied to sample data in your question - output is