I found this generic code online.
import pandas as pd
import holoviews as hv
from holoviews import opts, dim
from bokeh.sampledata.les_mis import data
hv.extension('bokeh')
hv.output(size=200)
links = pd.DataFrame(data['links'])
print(links.head(3))
hv.Chord(links)
nodes = hv.Dataset(pd.DataFrame(data['nodes']), 'index')
nodes.data.head()
chord = hv.Chord((links, nodes)).select(value=(5, None))
chord.opts(
opts.Chord(cmap='Category20', edge_cmap='Category20', edge_color=dim('source').str(),
labels='name', node_color=dim('index').str()))
That makes this, which looks nice.
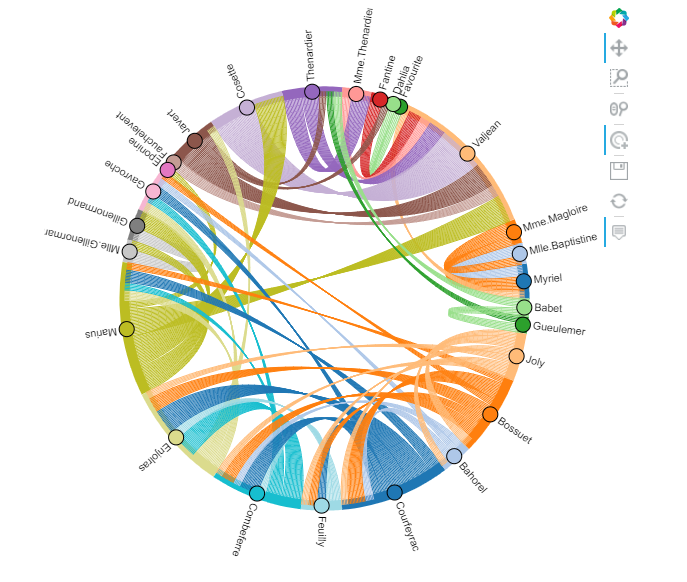
The sample data is sourced from here.
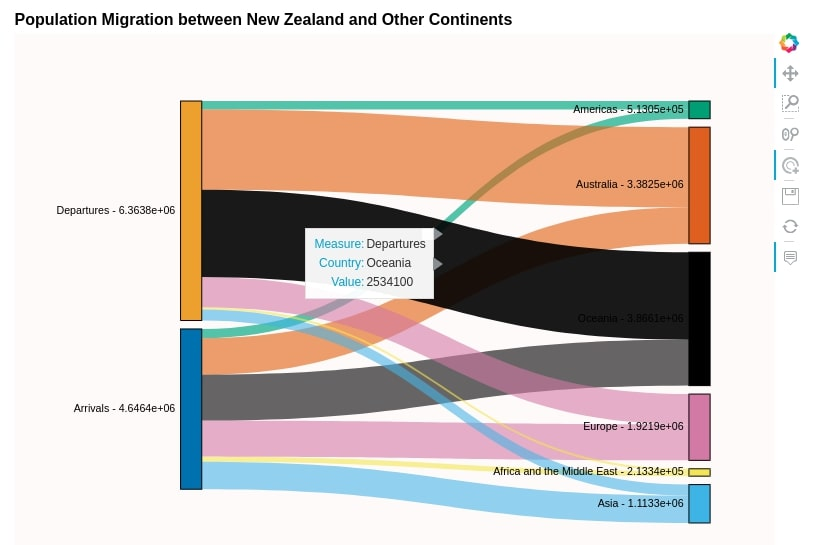
hv.Sankey(continent_wise_migration)
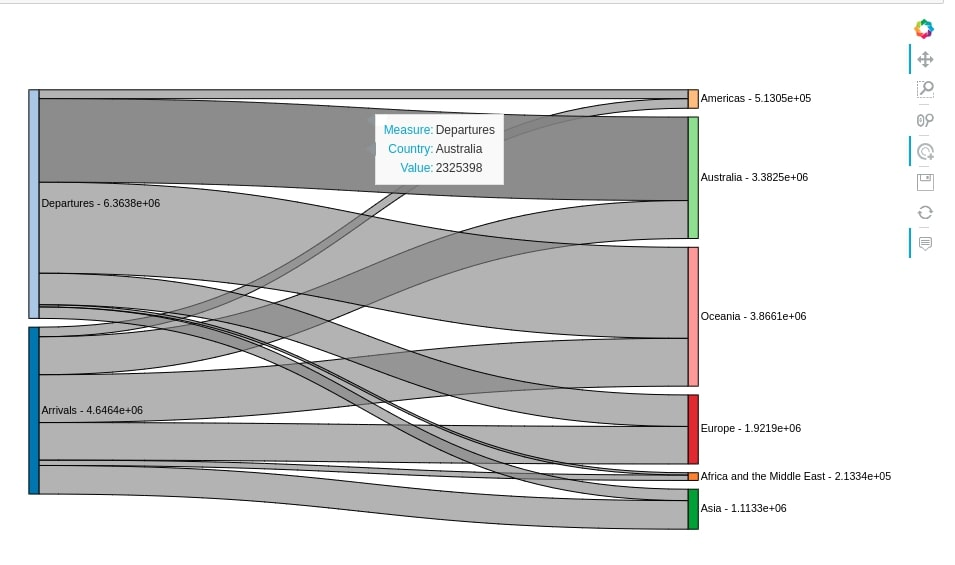
sankey1 = hv.Sankey(continent_wise_migration, kdims=["Measure", "Country"], vdims=["Value"])
sankey1.opts(cmap='Colorblind',label_position='left',
edge_color='Country', edge_line_width=0,
node_alpha=1.0, node_width=40, node_sort=True,
width=800, height=600, bgcolor="snow",
title="Population Migration between New Zealand and Other Continents")
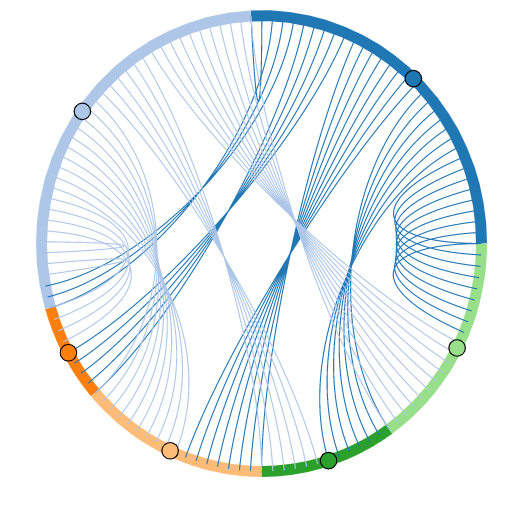
import pandas as pd
import numpy as np
import warnings
from holoviews import opts, dim
warnings.filterwarnings("ignore")
pd.set_option("max_columns", 30)
import holoviews as hv
hv.extension("bokeh")
hv.extension("matplotlib")
hv.output(fig='svg', size=250)
# conver to categories; numberics
df_fin = pd.DataFrame({col: continent_wise_migration[col].astype('category').cat.codes for col in continent_wise_migration}, index=continent_wise_migration.index)
df_fin.head(10)
chord = hv.Chord(df_fin).select(value=(5, None))
chord.opts(
opts.Chord(cmap='Category20', edge_cmap='Category20',
edge_color=dim('Measure').str(),
labels='Country',
node_color=dim('index').str()))
# finally...
import pandas as pd
from pandas import DataFrame
# Intitialise data of lists
data = [{'Measure': 'Arrivals', 'Country':'Greece', 'Value':'1590'},
{'Measure': 'Arrivals', 'Country':'Spain', 'Value':'1455'},
{'Measure': 'Arrivals', 'Country':'France', 'Value':'1345'},
{'Measure': 'Arrivals', 'Country':'Iceland', 'Value':'1100'},
{'Measure': 'Arrivals', 'Country':'Iceland', 'Value':'1850'},
{'Measure': 'Departures', 'Country':'America', 'Value':'2100'},
{'Measure': 'Departures', 'Country':'Ireland', 'Value':'1000'},
{'Measure': 'Departures', 'Country':'America', 'Value':'950'},
{'Measure': 'Departures', 'Country':'Ireland', 'Value':'1200'},
{'Measure': 'Departures', 'Country':'Japan', 'Value':'1050'},]
df = pd.DataFrame(data)
df
_list = list(df.Country.values)
new_df = pd.DataFrame({'From':_list, 'To':_list[3:] _list[:3], 'Value':df.Value})
node = pd.DataFrame()
for i, value in enumerate(df.Measure.unique()):
_list = list(df[df['Measure']==value].Country.unique())
node = pd.concat([node, pd.DataFrame({'Name':_list, 'Group':i})], ignore_index=True)
values = list(df.Country.unique())
d = {value: i for i, value in enumerate(values)}
def str2num(s):
return d[s]
new_df.From = new_df.From.apply(str2num)
new_df.To = new_df.To.apply(str2num)
hv.Chord(new_df)
nodes = hv.Dataset(pd.DataFrame(node), 'index')
chord = hv.Chord((new_df, nodes)).select(value=(5, None))
chord.opts(
opts.Chord(cmap='Category20', edge_cmap='Category20', edge_color=dim('From').str(),
labels='Name', node_color=dim('index').str()
)
)
CodePudding user response:
I think your data does not match the requirements of this function. Let me explain why I think so?
The Chord-function expects at least on dataset (this can be a pandas DataFrame) with three columns, but all elements are numbers.
source target value
0 1 0 1
1 2 0 8
2 3 0 10
A second dataset is optional. This can take strings in the second columns to add labels for example.
index name group
0 0 a 0
1 1 b 0
2 2 c 0
Basic Example
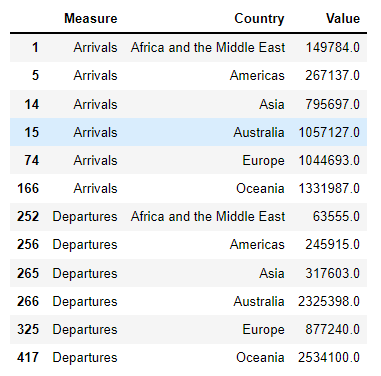
Your given data looks like this.
Measure Country Value
0 Arrivals Greece 1590
1 Arrivals Spain 1455
2 Arrivals France 1345
3 Arrivals Iceland 1100
4 Arrivals Iceland 1850
5 Departures America 2100
6 Departures Ireland 1000
7 Departures America 950
8 Departures Ireland 1200
9 Departures Japan 1050
You can bring your date in the basic form, if you replace the strings in your DataFrame df by numbers like this:
_df = df.copy()
values = list(_df.Measure.unique()) list(_df.Country.unique())
d = {value: i for i, value in enumerate(values)}
def str2num(s):
return d[s]
_df.Measure = _df.Measure.apply(str2num)
_df.Country = _df.Country.apply(str2num)
>>> df
Measure Country Value
0 0 2 1590
1 0 3 1455
2 0 4 1345
3 0 5 1100
4 0 5 1850
5 1 6 2100
6 1 7 1000
7 1 6 950
8 1 7 1200
9 1 8 1050
Now your data matches the basic conditions and you can create a Chord diagram.
chord = hv.Chord(_df).select(value=(5, None))
chord.opts(
opts.Chord(cmap='Category20', edge_cmap='Category20',
edge_color=dim('Measure').str(),
labels='Country',
node_color=dim('index').str()))
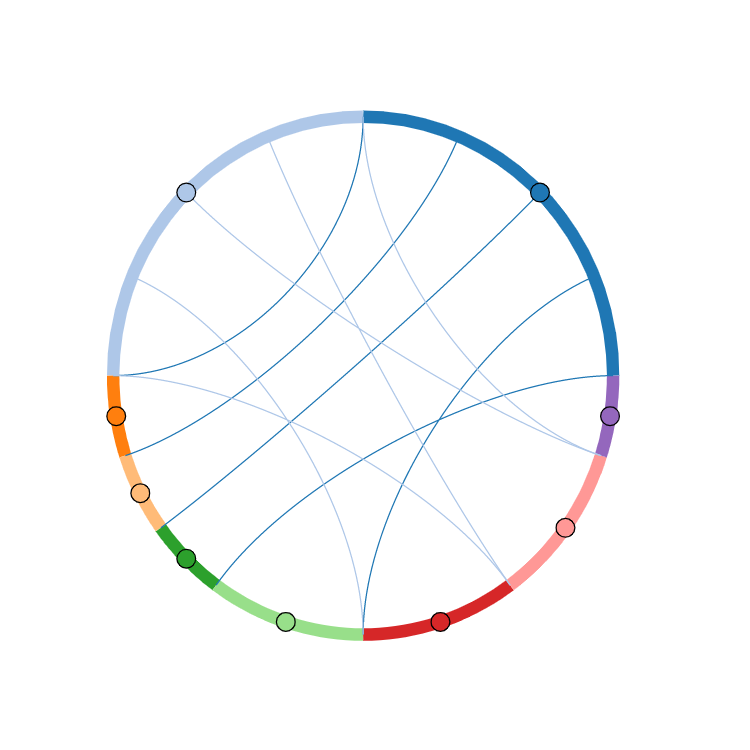
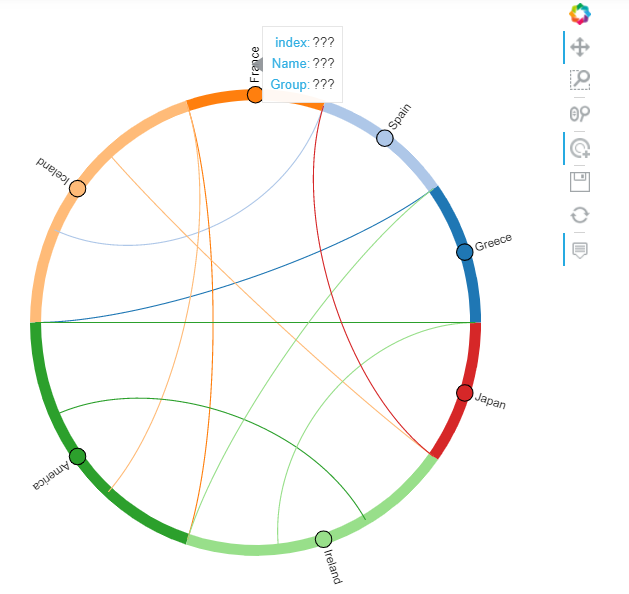
As you can see, all the conection lines only have one of two colors. This is because in the Measure column are only two elements. Therefor I think, this is not what you want.
Modificated Example
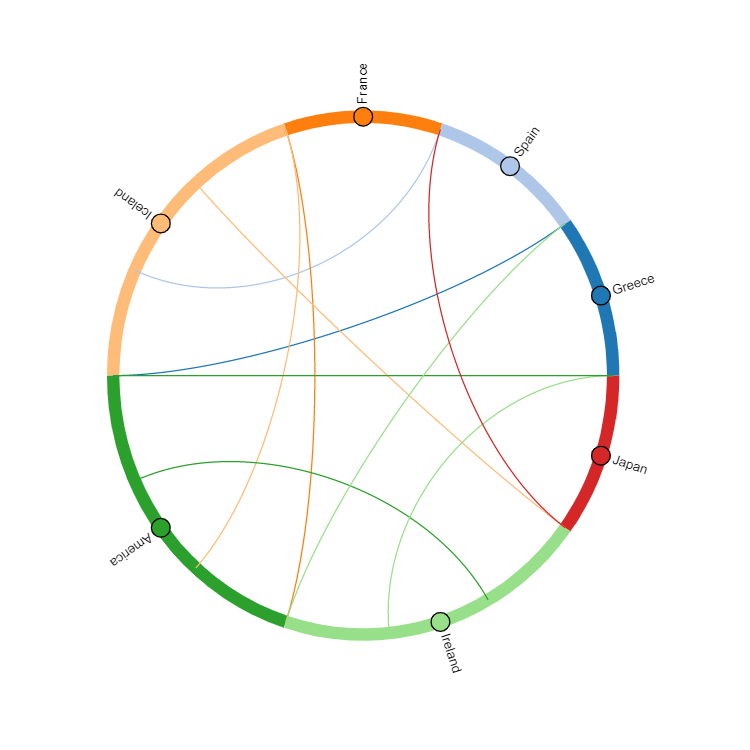
Let's Modify your data a tiny bit:
_list = list(df.Country.values)
new_df = pd.DataFrame({'From':_list, 'To':_list[3:] _list[:3], 'Value':df.Value})
>>> new_df
From To Value
0 Greece Iceland 1590
1 Spain Iceland 1455
2 France America 1345
3 Iceland Ireland 1100
4 Iceland America 1850
5 America Ireland 2100
6 Ireland Japan 1000
7 America Greece 950
8 Ireland Spain 1200
9 Japan France 1050
and:
node = pd.DataFrame()
for i, value in enumerate(df.Measure.unique()):
_list = list(df[df['Measure']==value].Country.unique())
node = pd.concat([node, pd.DataFrame({'Name':_list, 'Group':i})], ignore_index=True)
>>> node
Name Group
0 Greece 0
1 Spain 0
2 France 0
3 Iceland 0
4 America 1
5 Ireland 1
6 Japan 1
Now we have to replace the strings in new_df again and can call the Chord-function again.
values = list(df.Country.unique())
d = {value: i for i, value in enumerate(values)}
def str2num(s):
return d[s]
new_df.From = new_df.From.apply(str2num)
new_df.To = new_df.To.apply(str2num)
hv.Chord(new_df)
nodes = hv.Dataset(pd.DataFrame(node), 'index')
chord = hv.Chord((new_df, nodes)).select(value=(5, None))
chord.opts(
opts.Chord(cmap='Category20', edge_cmap='Category20', edge_color=dim('From').str(),
labels='Name', node_color=dim('index').str()
)
)
The are now two groups added to the HoverTool.