I have a dataframe with multiple columns, eg:
Name Age Fname
0 Alex 10 Alice
1 Bob 12 Bob
2 Clarke 13 clarke
My filter condition is to check if Name is (case-insensitive) substring of corresponding Fname.
If it was equality, something as simple as:
df[df["Name"].str.lower() == df["Fname"].str.lower()]
works. However, I want substring match, so instead of ==, I thought in would work. But that gives error as it interprets one of the arguments as pd.Series. My 1st question is Why this difference in interpretation?
Another way I tried was using .str.contains:
df[df["Fname"].str.contains(df["Name"], case=False)]
which also interprets df["Name"] as pd.Series, and of course, works for some const string in the argument.
eg. this works:
df[df["Fname"].str.contains("a", case=False)]
I want to resolve this situation, so any help in that regard is appreciated.
CodePudding user response:
You can iterate over index axis:
>>> df[df.apply(lambda x: x['Name'].lower() in x['Fname'].lower(), axis=1)]
Name Age Fname
1 Bob 12 Bob
2 Clarke 13 clarke
str.contains takes a constant in first argument pat not a Series.
CodePudding user response:
You could use .apply() with axis=1 to call a function for each row:
subset = df[df.apply(lambda x: x['Name'].lower() in x['Fname'].lower(), axis=1)]
Output:
>>> subset
Name Age Fname
1 Bob 12 Bob
2 Clarke 13 clarke
CodePudding user response:
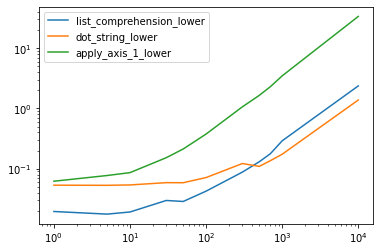
The .str accessor is extremely loopy and slow. It is best most of the times using list comprehension.
import pandas as pd
import numpy as np
import timeit
import matplotlib.pyplot as plt
import pandas.testing as pt
def list_comprehension_lower(df):
return df[[len(set(i)) == 1 for i in (zip([x.lower() for x in df['Name']],[y.lower() for y in df['Fname']]))]]
def apply_axis_1_lower(df):
return df[df.apply(lambda x: x['Name'].lower() in x['Fname'].lower(), axis=1)]
def dot_string_lower(df):
return df[df["Name"].str.lower() == df["Fname"].str.lower()]
fig, ax = plt.subplots()
res = pd.DataFrame(
index=[1, 5, 10, 30, 50, 100, 300, 500, 700, 1000, 10000],
columns='list_comprehension_lower apply_axis_1_lower dot_string_lower'.split(),
dtype=float
)
for i in res.index:
d = pd.concat([df]*i, ignore_index=True)
for j in res.columns:
stmt = '{}(d)'.format(j)
setp = 'from __main__ import d, {}'.format(j)
res.at[i, j] = timeit.timeit(stmt, setp, number=100)
res.groupby(res.columns.str[4:-1], axis=1).plot(loglog=True, ax=ax);
Output:
Now, back you your original question, You can use list_comprehension with zip and in:
df.loc[2, 'Fname'] = ' Adams'
df[[x in y for x, y in zip([x.lower() for x in df['Name']],[y.lower() for y in df['Fname']])]]
Output:
Name Age Fname
1 Bob 12 Bob
2 Clarke 13 clarke Adams