I need most similar column file, I have data:
Input:
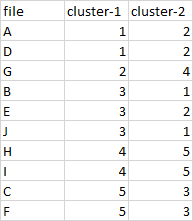
I need cluster-1 to be equal to cluster-2 in the maximum count, a file that will not be specified not to be included in the cluster
Output:
CodePudding user response:
Compare first Series.mode per groups by original column, filter and if necessary add not filtered rows with assign bin to cluster-2:
print (df)
file cluster-1 cluster-2
0 A 1 2
1 D 1 2
2 G 2 4
3 B 3 1
4 E 3 2
5 J 3 1
m = (df.groupby('cluster-1')['cluster-2']
.transform(lambda x: x.mode().iat[0])
.eq(df['cluster-2']))
df = (df[m].append(df[~m].assign(**{'cluster-1':'bin'}), ignore_index=True)
.rename(columns={'cluster-1':'cluster'})
.drop('cluster-2', axis=1))
print (df)
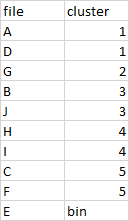
file cluster
0 A 1
1 D 1
2 G 2
3 B 3
4 J 3
5 E bin