I am trying to read the text from a .png file, but unable to get the proper output.
Here is the code I have tried:
from PIL import Image
from pytesseract import pytesseract
path_to_tesseract = r"Path_to Tesseract-OCR.exe"
image_path = r"Path to png file"
img = Image.open(image_path)
pytesseract.tesseract_cmd = path_to_tesseract
text = pytesseract.image_to_string(img)
print(text)
The output I'm getting is something like this: m _ an I: umonfé ‘
Input .png file:

The expected output is LG485169046
CodePudding user response:
I would like to suggest you using 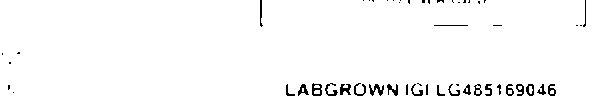
Output will be:
LABGROWN IGI LG485169046
If you only want the last part, you could do:
>>> print(text.split(" ")[3])
LG485169046
Code:
import cv2
import pytesseract
# Load the image
img = cv2.imread("KfzeJ.png")
# Resize the image
img = cv2.resize(img, None, fx=2, fy=2)
# Convert to the hsv color-space
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# Get binary-mask
msk = cv2.inRange(hsv, array([0, 0, 0]), array([179, 255, 80]))
krn = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 3))
dlt = cv2.dilate(msk, krn, iterations=1)
thr = 255 - cv2.bitwise_and(dlt, msk)
# OCR
txt = pytesseract.image_to_string(thr)
print(txt.split(" ")[3])
P.S. Pytesseract version: 0.3.8
CodePudding user response:
Step1- try to add the "Path_to Tesseract-OCR.exe" to your environment variable.
Step2- if step1 not worked try to use passporteye package.