I'm trying to write a grammar for Prolog interpreter. When I run grun from command line on input like "father(john,mary).", I get a message saying "no viable input at 'father(john,'" and I don't know why. I've tried rearranging rules in my grammar, used different entry points etc., but still get the same error. I'm not even sure if it's caused by my grammar or something else like antlr itself. Can someone point out what is wrong with my grammar or think of what could be the cause if not the grammar?
The commands I ran are:
antlr4 -no-listener -visitor Expr.g4
javac *.java
grun antlr.Expr start tests/test.txt -gui
And this is the resulting parse tree:
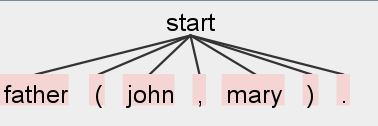
Here is my grammar:
grammar Expr;
@header{
package antlr;
}
//start rule
start : (program | query) EOF
;
program : (rule_ '.')*
;
query : conjunction '?'
;
rule_ : compound
| compound ':-' conjunction
;
conjunction : compound
| compound ',' conjunction
;
compound : Atom '(' elements ')'
| '.(' elements ')'
;
list : '[]'
| '[' element ']'
| '[' elements ']'
;
element : Term
| list
| compound
;
elements : element
| element ',' elements
;
WS : [ \t\r\n] -> skip ;
Atom : [a-z]([a-z]|[A-Z]|[0-9]|'_')*
| '0'
;
Var : [A-Z]([a-z]|[A-Z]|[0-9]|'_')*
;
Term : Atom
| Var
;
CodePudding user response:
The lexer will always produce the same tokens for any input. The lexer does not "listen" to what the parser is trying to match. The rules the lexer applies are quite simple:
- try to match as many characters as possible
- when 2 or more lexer rules match the same amount of characters, let the rule defined first "win"
Because of the 2nd rule, the rule Term will never be matched. And moving the Term rule above Var and Atom will cause the latter rules to be never matched. The solution: "promote" the Term rule to a parser rule:
start : (program | query) EOF
;
program : (rule_ '.')*
;
query : conjunction '?'
;
rule_ : compound (':-' conjunction)?
;
conjunction : compound (',' conjunction)?
;
compound : Atom '(' elements ')'
| '.' '(' elements ')'
;
list : '[' elements? ']'
;
element : term
| list
| compound
;
elements : element (',' element)*
;
term : Atom
| Var
;
WS : [ \t\r\n] -> skip ;
Atom : [a-z] [a-zA-Z0-9_]*
| '0'
;
Var : [A-Z] [a-zA-Z0-9_]*
;