I have the dataframe underneath:
df = pd.DataFrame(np.array(['YM.296','MM.305','VO.081.019','VO.081.016','AM.081.002.001','AM081','SR.082','VO.081.012.001','VO.081.012.003']))
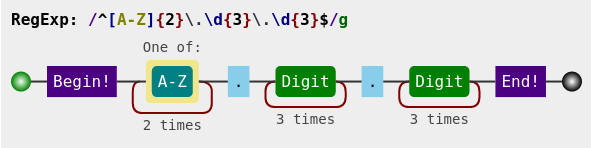
I want to know in what row the syntax is similar to 'XX.222.333' (example). So two letters followed by a stop ('.') followed by three numbers followed by a stop ('.') followed by three numbers again.
The desired outcome looks as follows:
tf = pd.DataFrame(np.array([False,False,True,True,False,False,False,False, False]))
Is there a fast and pythonic way to do this?
CodePudding user response:
You can do that using str.contains and regex.
As follows:
df[0].str.contains(r'^[A-Z]{2}\.\d{3}\.\d{3}$', regex=True)
Outputs:
0 False
1 False
2 True
3 True
4 False
5 False
6 False
Name: 0, dtype: bool
Here is a visualization of the regex used: