I have the following code:
import pandas as pd
from pandas import DataFrame as df
import matplotlib
from pandas_datareader import data as web
import matplotlib.pyplot as plt
import datetime
import warnings
warnings.filterwarnings("ignore")
from matplotlib import dates as mdates
start = datetime.date(2021,1,1)
end = datetime.date.today()
stock = 'fb'
data = web.DataReader(stock, 'yahoo', start, end)
data.index = pd.to_datetime(data.index, format ='%Y-%m-%d')
data = data[~data.index.duplicated(keep='first')]
data.reset_index()
data['month'] = data.index.month
data['week'] = data.index.week
data['day'] = data.index.day
data = data.reset_index()
del data['Date']
data.set_index('month',append=True,inplace=True)
data.set_index('week',append=True,inplace=True)
data.set_index('day',append=True,inplace=True)
fig, ax = plt.subplots(dpi=300, figsize =(15,4))
plt.plot(data.index.get_level_values(0), data['Close'])
locator = mdates.MonthLocator()
formatter = mdates.ConciseDateFormatter(locator)
ax.xaxis.set_major_locator(locator)
ax.xaxis.set_major_formatter(formatter)
plt.show()
This code produces the following dataframe:
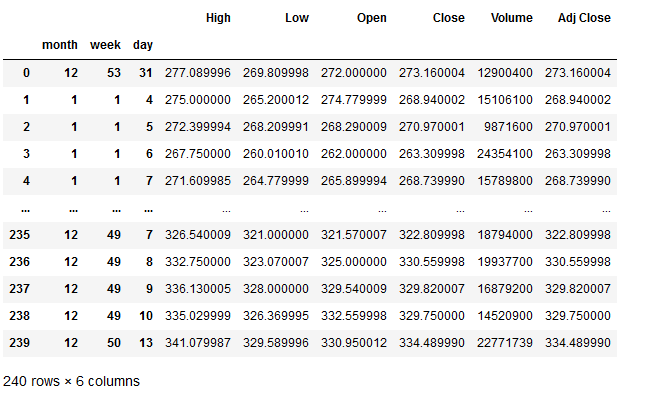
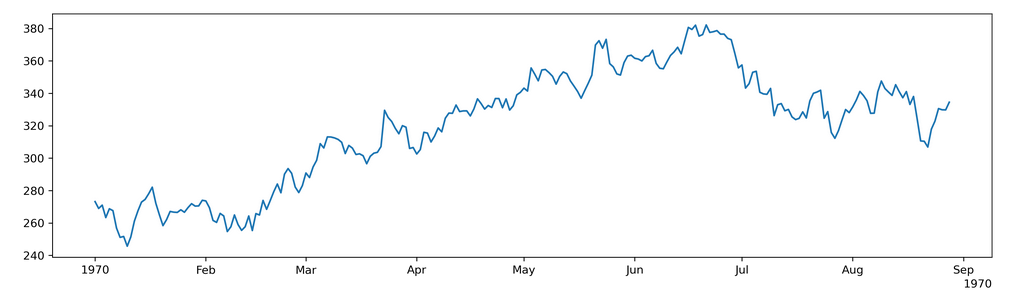
As you can see there is no year in the data. In this particular case i had removed the year because the data i am looking to analyze is not a financial time series data. As such I need the plot to start from Jan instead of it printing 1970. So with mdates.MonthLocator() it is adding 1970 on the x-axis of the plot. Is there any way i can remove the year label and have the plot start from Jan?
CodePudding user response:
I believe that is a bug. I suggest turning month, week, day into a single column as datetime object.
import numpy as np
import pandas as pd
pd.set_option('display.max_rows', 1000)
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
date = np.array([1, 2, 3, 4, 5], dtype='str')
month = np.array([1, 2, 3, 4, 5], dtype='str')
year = np.array([2012, 2012, 2012, 2012, 2012, ], dtype='str')
df = pd.DataFrame({'date': date,
'month': month,
'year': year})
datetime = []
i, x, y = df.date, df.month, df.year
datetime.append(i '/' x '/' y)
for i in datetime:
df = df.assign(FullDate=i)
print(df)
Output:
date month year FullDate
0 1 1 2012 1/1/2012
1 2 2 2012 2/2/2012
2 3 3 2012 3/3/2012
3 4 4 2012 4/4/2012
4 5 5 2012 5/5/2012
Process finished with exit code 0
Then, use it as your x axis. This way PYPLOT API will automatically detect duplicates and show a similar axis but without the bug - hopefully.
There is also the option of ax1.set_xticklabels(labels=['']) which you can configure manually to change the x axis labels and potentially remove them.