I have a table in the following form
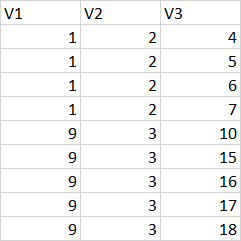
I want to keep only the first 3 rows based on duplicate values of V1 & V@ like below:
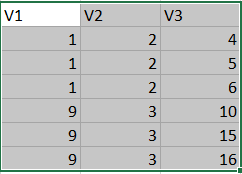
df %>% distinct(V1,V2) only let me keep the first row.
CodePudding user response:
You may try
library(dplyr)
df %>%
group_by(V1, V2) %>%
filter(row_number() <= 3)
V1 V2 V3
<dbl> <dbl> <dbl>
1 1 2 4
2 1 2 5
3 1 2 6
4 9 3 10
5 9 3 15
6 9 3 16
CodePudding user response:
With data.table:
library(data.table)
dt <- data.table(c(rep(1, 4), rep(9, 5)), c(rep(2, 4), rep(3, 5)), c(4:7, 10, 15:18))
dt[, .SD[1:3], by = c('V1', 'V2')]
V1 V2 V3
1: 1 2 4
2: 1 2 5
3: 1 2 6
4: 9 3 10
5: 9 3 15
6: 9 3 16
You can use .SD[1:min(3, .N)] if you don't want a row with V3 = NA if there are less than 3 duplicates.