I am learning Convolution Neural Network now and practicing it on Pytorch. Recently, I have been reading papers related to optimizers, such as SGD,Adam,and Radam.
When looking at the visual results of papers, I found that their images showed a sudden increase in accuracy at the 80th epoch( the figure6 in paper "ON THE VARIANCE OF THE ADAPTIVE LEARNING RATE AND BEYOND" )
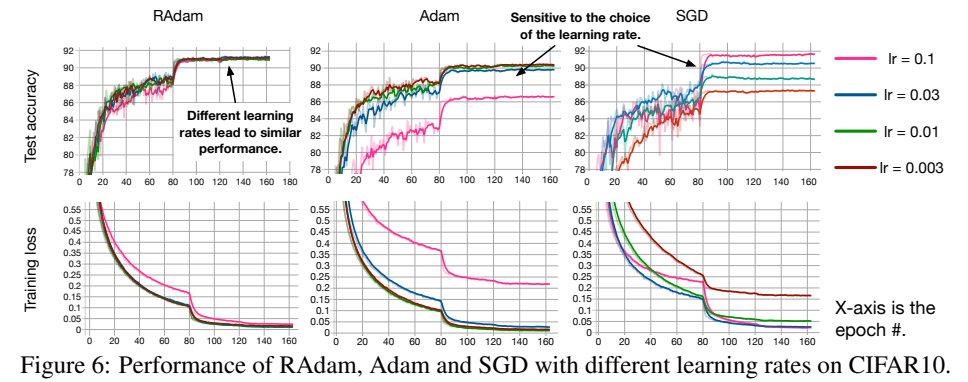
or 150th epoch(the figure3 in paper"ADAPTIVE GRADIENT METHODS WITH DYNAMICBOUND OF LEARNING RATE")
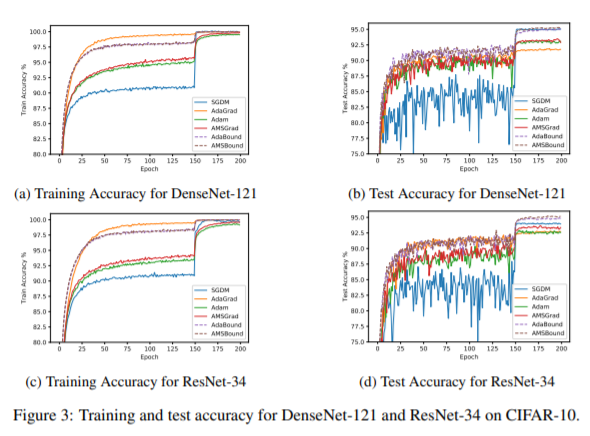
no matter what kind of algorithm.
Can anyone tell me why this happened? Thank you.
CodePudding user response:
If your implementation is correct, this could mean that your model learns something very useful at this moment (so your gradient descent finds a revine). For example, model has to learn by itself the correct normalization of the inputs. It's not very unusual to see that loss has this kind of "stair-step" loss graph, I've seen this before (but don't remember where exactly).
This could also mean that you're using inefficient weights initialization, so that your optimization algorithm has to manually find the best correct one.
CodePudding user response:
They decrease learning rate by much. Probably they start with too big learning rate to get some "average" model fast, then decrease learning rate to tune this model to better level of accuracy. There are many methods of training with decreasing learning rate. They've chose such.
In the paper "ADAPTIVE GRADIENT METHODS WITH DYNAMICBOUND OF LEARNING RATE" they say they decreae learning rate:
we employ the fixed budget of 200 epochs and reduce the learning rates by 10 after 150 epochs
Probably in the other paper they do the same, but they did not write about it.