I have list like this(simplified version):
data = [{'layer1': [{'idx': 'idx_102',
'size': 8 },
{'idx': 'idx_112',
'size': 25 },
{'idx': 'idx_142',
'size': 10 }]
},
{'layer2': [{'idx': 'idx_125',
'size': 28 },
{'idx': 'idx_258',
'size': 21 },
{'idx': 'idx_658',
'size': 12 }]
},
{'layer3': [{'idx': 'idx_158',
'size': 78 }]
}]
The structure of the excel file should be like this:
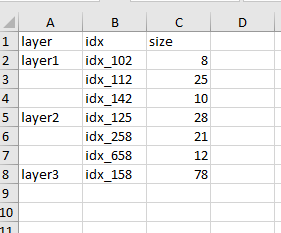
Can someone help, I am lost with Pandas
CodePudding user response:
Use nested list with dict comprehensions:
L = [{**{'layer': k}, **x} for d in data for k, v in d.items() for x in v]
df = pd.DataFrame(L)
print (df)
layer idx size
0 layer1 idx_102 8
1 layer1 idx_112 25
2 layer1 idx_142 10
3 layer2 idx_125 28
4 layer2 idx_258 21
5 layer2 idx_658 12
6 layer3 idx_158 78
Last if need remove duplicates:
df.loc[df['layer'].duplicated(), 'layer'] = ''
print (df)
layer idx size
0 layer1 idx_102 8
1 idx_112 25
2 idx_142 10
3 layer2 idx_125 28
4 idx_258 21
5 idx_658 12
6 layer3 idx_158 78