For example, I have a pandas dataframe like this :
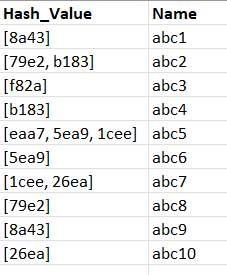
Ignoring the "Name" column, I want a dataframe that looks like this, labelling the Hashes of the same group with their "ID"
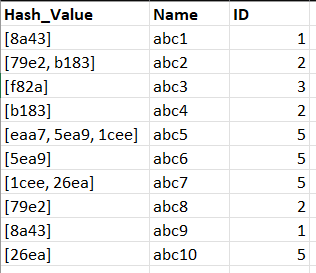
Here, we traverse each row, we encounter "8a43", and assign ID 1 to it, and wherever we find the same hash value, we assign ID as 1. Then we move on to the next row, and encounter 79e2 and b183. We then traverse all the rows and wherever we find these values, we store their IDs as 2. Now the issue will arise when we reach "abc7". It will be assigned ID=5 as it was previously encountered in "abc5". But I also want that in rows after the current one, wherever I find "26ea", assign the ID=5 to those as well.
I hope all this makes sense. If not, feel free to reach out to me via comments or message. I will clear it out quickly.
CodePudding user response:
Solution using dict
import numpy as np
import pandas as pd
hashvalues = list(df['Hash_Value'])
dic, i = {}, 1
id_list = []
for hashlist in hashvalues:
# convert to list
if isinstance(hashlist, str):
hashlist = hashlist.replace('[','').replace(']', '')
hashlist = hashlist.split(',')
# check if the hash is unknown
if hashlist[0] not in dic:
# Assign a new id
dic[hashlist[0]] = i
k = i
i = 1
else:
# if known use existing id
k = dic[hashlist[0]]
for h in hashlist[1:]:
# set id of the rest of the list hashes
# equal to the first hashes's id
dic[h] = k
id_list.append(k)
else:
id_list.append(np.nan)
print(df)
Hash Name ID
0 [8a43] abc1 1
1 [79e2,b183] abc2 2
2 [f82a] abc3 3
3 [b183] abc4 2
4 [eaa7,5ea9,1cee] abc5 4
5 [5ea9] abc6 4
6 [1cee,26ea] abc7 4
7 [79e2] abc8 2
8 [8a43] abc9 1
9 [26ea] abc10 4
CodePudding user response:
Use networkx solution for dictionary for common values, select first value in Hash_Value by str and use Series.map:
#if necessary convert to lists
#df['Hash_Value'] = df['Hash_Value'].str.strip('[]').str.split(', ')
import networkx as nx
G=nx.Graph()
for l in df['Hash_Value']:
nx.add_path(G, l)
new = list(nx.connected_components(G))
print (new)
[{'8a43'}, {'79e2', 'b183'}, {'f82a'}, {'5ea9', '1cee', '26ea', 'eaa7'}]
mapped = {node: cid for cid, component in enumerate(new) for node in component}
df['ID'] = df['Hash_Value'].str[0].map(mapped) 1
print (df)
Hash_Value Name ID
0 [8a43] abcl 1
1 [79e2, b183] abc2 2
2 [f82a] abc3 3
3 [b183] abc4 2
4 [eaa7, 5ea9, 1cee] abc5 4
5 [5ea9] abc6 4
6 [1cee, 26ea] abc7 4
7 [79e2] abc8 2
8 [8a43] abc9 1
9 [26ea] abc10 4