I try to read vertically a csv file as follow to insert in graphite/carbon timeseries DB with python.
"No.","time","00:00:00","00:00:01","00:00:02","00:00:03","00:00:04","00:00:05","00:00:06","00:00:07","00:00:08","00:00:09","00:00:0A"
"1","2021/09/12 02:16",235,610,345,997,446,130,129,94,555,274,4
"2","2021/09/12 02:17",364,210,371,341,294,87,179,106,425,262,3
"3","2021/09/12 02:18",297,343,860,216,275,81,73,113,566,274,3
"4","2021/09/12 02:19",305,243,448,262,387,64,63,119,633,249,3
"5","2021/09/12 02:20",276,151,164,263,315,86,92,175,591,291,1
"6","2021/09/12 02:21",264,343,287,542,312,83,72,122,630,273,4
"7","2021/09/12 02:22",373,157,266,446,246,90,173,90,442,273,2
"8","2021/09/12 02:23",265,112,241,307,329,64,71,82,515,260,3
"9","2021/09/12 02:24",285,247,240,372,176,92,67,83,609,620,1
"10","2021/09/12 02:25",289,964,277,476,356,84,74,104,560,294,1
"11","2021/09/12 02:26",279,747,227,573,569,82,77,99,589,229,5
"12","2021/09/12 02:27",338,370,315,439,653,85,165,346,367,281,2
"13","2021/09/12 02:28",269,135,372,262,307,73,86,93,512,283,4
"14","2021/09/12 02:29",281,207,688,322,233,75,69,85,663,276,2
I wish to build a dictionary "tuples" content as follow : In facts, i need to write the header of each column with the value of each time, with the date convert to epoch time:
"2021/09/12 02:16" = epoch 1631405760
tuples.append(('perf.type.serial.object.00:00:00.TOTAL_IOPS', (1631405760 ,235)))
tuples.append(('perf.type.serial.object.00:00:00.TOTAL_IOPS', (1631405820 ,364)))
...
tuples.append(('perf.type.serial.object.00:00:01.TOTAL_IOPS', (1631405760 ,610)))
tuples.append(('perf.type.serial.object.00:00:01.TOTAL_IOPS', (1631405820 ,210)))
I'm able to list the header, but i don't know how to keep the date and value for each
import csv
def read_csv(file_path):
with open(file_path, 'rt') as f:
csv_reader = csv.reader(f, delimiter=',')
for line in csv_reader:
print(line)
tuples.append(('perf.type.serial.object.header.col.TOTAL_IOPS', (1631405760 ,235))) ?
read_csv('my.csv')
Many thanks for any help
CodePudding user response:
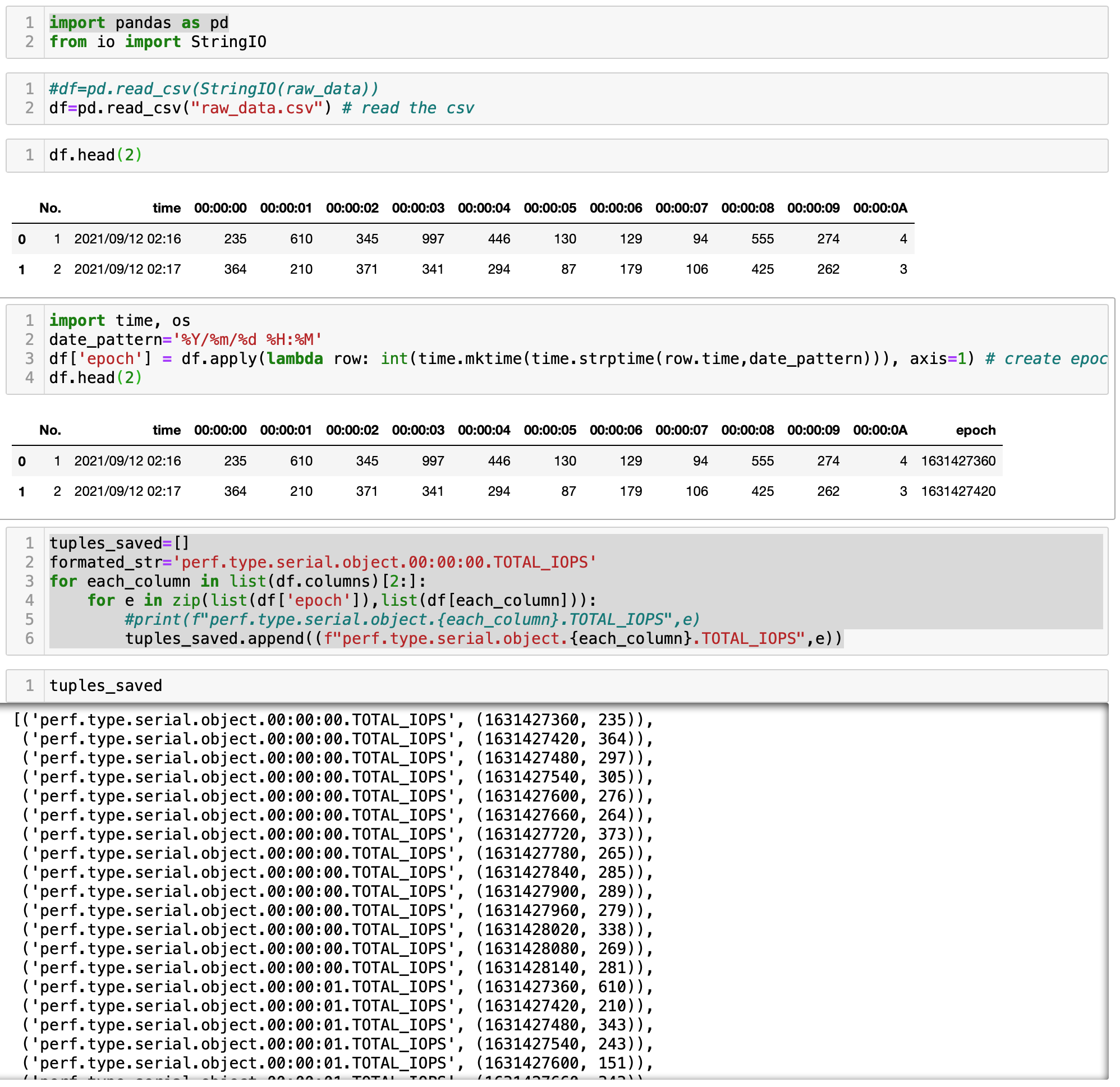
- Read the csv file.
import pandas as pd
df=pd.read_csv("raw_data.csv") # read the csv
- Add the new column value, please tweak to your epoch logic.
import time, os
date_pattern='%Y/%m/%d %H:%M'
df['epoch'] = df.apply(lambda row: int(time.mktime(time.strptime(row.time,date_pattern))), axis=1) # create epoch as a column
df
- save the data in the list or any ds as needed.
tuples_saved=[] # data will be saved in a list
formated_str='perf.type.serial.object.00:00:00.TOTAL_IOPS'
for each_column in list(df.columns)[2:]:
for e in zip(list(df['epoch']),list(df[each_column])):
#print(f"perf.type.serial.object.{each_column}.TOTAL_IOPS",e)
tuples_saved.append((f"perf.type.serial.object.{each_column}.TOTAL_IOPS",e))
CodePudding user response:
Try using this.
with open(file_path, 'r') as f:
csv_reader = csv.reader(f, delimiter=',')
dict_from_csv={rows[0]:rows[1] for rows in csv_reader}
print(dict_from_csv)