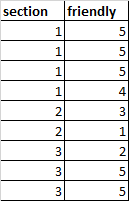
Please help me understand what will be the best way to do the transformation of pandas DataFrame in the image shown below.
dct = {'section': {0: 1, 1: 1, 2: 1, 3: 1, 4: 2, 5: 2, 6: 3, 7: 3, 8: 3},
'friendly': {0: 5, 1: 5, 2: 5, 3: 4, 4: 3, 5: 1, 6: 2, 7: 5, 8: 5}}
df = pd.DataFrame(dct)
5 : Excellent 4 : Very Good 3 : Good 2 : Just Okay 1 : Poor
INPUT :
OUTPUT :

CodePudding user response:
Use crosstab for count, then get percentages to df2 by divide by sum, join by concat with keys for MultiIndex, sorting it and flatten in map:
d = {5 : 'Excellent', 4 : 'Very Good', 3 : 'Good', 2 : 'Just Okay', 1 : 'Poor'}
df1 = pd.crosstab(df['section'], df['friendly'])
df2 = df1.div(df1.sum(axis=1), axis=0).mul(100).round().astype(int)
df = (pd.concat([df1, df2], keys=('Count','Per'), axis=1)
.sort_index(axis=1, ascending=[False, True], level=[1,0])
.rename(columns=d))
df.columns = df.columns.map(lambda x: f'{x[1]}_{x[0]}')
df = df.reset_index()
print (df)
section Excellent_Count Excellent_Per Very Good_Count Very Good_Per \
0 1 3 75 1 25
1 2 0 0 0 0
2 3 2 67 0 0
Good_Count Good_Per Just Okay_Count Just Okay_Per Poor_Count Poor_Per
0 0 0 0 0 0 0
1 1 50 0 0 1 50
2 0 0 1 33 0 0