I am using Selenium to extract data from the following page.
Page url: www2.miami-dadeclerk.com/cef/CitationSearch.aspx
Click on Folio: 0131230371470 . Click on the first one.
I have used the following code to extract certain information:
templist = []
status = driver.find_element_by_xpath('.//*[@id="lblCitationHeader"]').text
total_due = driver.find_element_by_xpath('.//*[@id="lblCitationHeader"]').text
issue_dept = driver.find_element_by_xpath('.//*[@id="form1"]/div[4]/div[9]/div/div/div[2]/table/tbody/tr[5]/td[2]').text
lien_placed = driver.find_element_by_xpath('.//*[@id="lblLienPlaced"]').text
Table_dict = {
'Status': status,
'Total Due': total_due,
'Issuing Department': issue_dept,
'Lien_Placed': lien_placed
}
templist.append(Table_dict)
df = pd.DataFrame(templist)
The result coming is as follows:
Status Total Due Issuing Department Lien_Placed
0 Citation No.: 2010 - S001916 Issue Date: 1/ ... Citation No.: 2010 - S001916 Issue Date: 1/ ... 05 ANIMAL SERVICES DEPARTMENT (305) 629-7387
Here all the data that is under lblCitationHeader is coming under Status and Total due.
For that I had extracted their Xpaths:
Status: //*[@id="lblCitationHeader"]/text()[3]
Total Due: //*[@id="lblCitationHeader"]/text()[4]
When I am entering the above in the code:
status = driver.find_element_by_xpath('.//*[@id="lblCitationHeader"]/text()[3]').text
The following error is coming:
Message: invalid selector: Unable to locate an element with the xpath expression .//*[@id="lblCitationHeader"]/text()[3]"] because of the following error:
SyntaxError: Failed to execute 'evaluate' on 'Document': The string './/*[@id="lblCitationHeader"]/text()[3]"]' is not a valid XPath expression.
(Session info: chrome=96.0.4664.110)
I understand Xpath is used to locate the element and not text. However I am not being able to locate the section in which the text is stored and return it.
Image for reference:
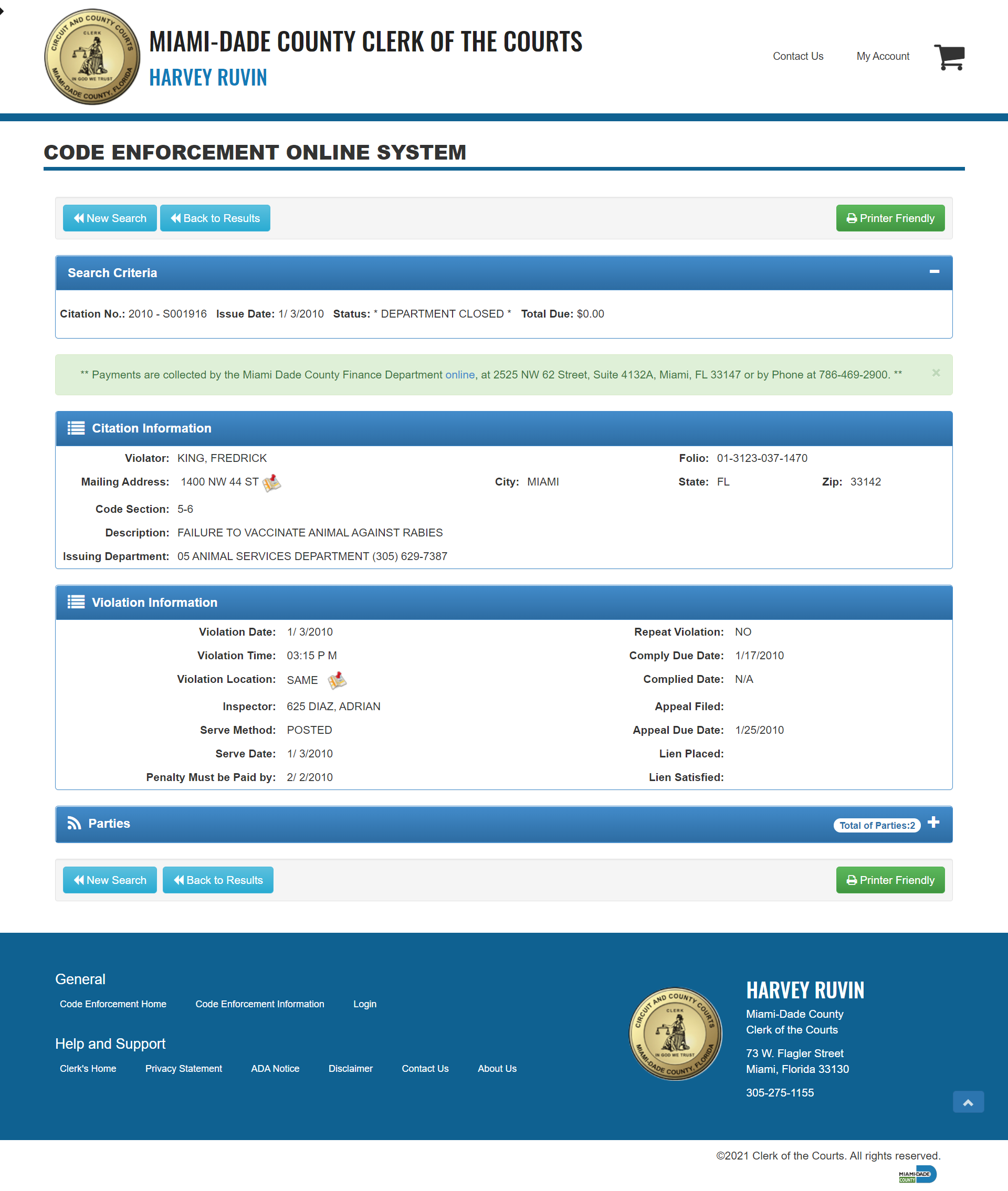
The data's I want to extract are:-
STATUS TOTAL DUE ISSUING DEPT LIEN PLACED
CodePudding user response:
For the current document STATUS TOTAL DUE and ISSUING DEPT fields have a value and to extract the values you need to induce WebDriverWait for the visibility_of_element_located() and you can use either of the following Locator Strategies:
Code Block:
driver.get("https://www2.miami-dadeclerk.com/cef/CitationSearch.aspx")
WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.LINK_TEXT, "Folio"))).click()
WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "input#txtFolioNumber"))).send_keys("0131230371470")
WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "input#btnFolioSearch"))).click()
WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "table tbody>tr>td>a>span"))).click()
status = driver.execute_script('return arguments[0].childNodes[5].textContent;', WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "span#lblCitationHeader")))).strip()
total_due = driver.execute_script('return arguments[0].lastChild.textContent;', WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.CSS_SELECTOR, "span#lblCitationHeader")))).strip()
issue_dept = WebDriverWait(driver, 20).until(EC.visibility_of_element_located((By.XPATH, "//strong[contains(., 'Issuing Department:')]//following::td[1]/span"))).text
print(f"{status}--{total_due}--{issue_dept}")
Console Output:
* DEPARTMENT CLOSED *--$0.00--05 ANIMAL SERVICES DEPARTMENT (305) 629-7387
Note : You have to add the following imports :
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC