I want to work with a parquet table with certain types of fields:
name_process: String id_session: String time_write: String key: String value: String
"id_session" is a id for SparkSession.
The table is partitioned by the "name_process" column
For example:
| name_process | id_session | time_write | key | value |
|---|---|---|---|---|
| OtherClass | sess000001 | 1639950466114000 | schema0.table0.csv | Success |
| OtherClass | sess000002 | 1639950466214000 | schema1.table1.csv | Success |
| OtherClass | sess000003 | 1639950466309000 | schema0.table0.csv | Success |
| OtherClass | sess000003 | 1639950466310000 | schema1.table1.csv | Failure |
| OtherClass | sess000003 | 1639950466311000 | schema2.table2.csv | Success |
| OtherClass | sess000003 | 1639950466312000 | schema3.table3.csv | Success |
| ExternalClass | sess000004 | 1639950466413000 | schema0.table0.csv | Success |
All values for the "key" column are unique only within one spark session (the "id_session" column). This happens because I work with the same files (csv) every time I start a spark session. I plan to send these files to the server. Both the time of sending and the response from the server will be recorded in the "time_write" and "value" columns. That is, I want to see the latest sending statuses for all csv files.
This is a log for entries that I will interact with. To interact with this log, I want to implement several methods:
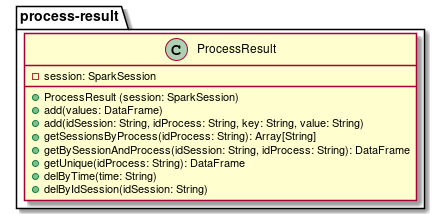
All getters methods will return filtered DateFrames with all columns. That is, the result remains 5 columns. I'm still having difficulties with API Spark. It will take some time until I learn how to perform beautiful operations on DataFrames. Here's what my result is:
abstract class ProcessResultBook(processName: String, onlyPartition: Boolean = true)(implicit spark: SparkSession) {
val pathTable = new File("/src/test/spark-warehouse/test_db.db/test_table").getAbsolutePath
val path = new Path(s"$pathTable${if(onlyPartition) s"/name_process=$processName" else ""}").toString
val df = spark.read.parquet(path)
def getLastSession: Dataset[Row] = {
val lastTime = df.select(max(col("time_write"))).collect()(0)(0).toString
val lastSession = df.select(col("id_session")).where(col("time_write") === lastTime).collect()(0)(0).toString
val dfByLastSession = df.filter(col("id_session") === lastSession)
dfByLastSession.show()
/*
---------- ---------------- ------------------ -------
|id_session| time_write| key| value|
---------- ---------------- ------------------ -------
|alskdfksjd|1639950466414000|schema2.table2.csv|Failure|
*/
dfByLastSession
}
def add(df: DataFrame) = ???
def add(processName: String, idSession: String, timeWrite: String, key: String, value: String) = ???
def getSessionsByProcess(processName: String) = ???
def getBySessionAndProcess(processName: String, idSession: String) = ???
def getUnique(processName: String) = ???
def delByTime(time: String) = ???
def delByIdSession(idSession: String) = ???
def getCurrentTime: SQLTimestamp = DateTimeUtils.fromMillis(TimeStamp.getCurrentTime.getTime)
def convertTime(time: Long): String = TimeStamp.getNtpTime(time).getDate.toString
}
And I have case class:
case class RowProcessResult(
nameProcess: String,
idSession: String,
timeWrite: String,
key: String,
value: String
)
Help to implement 2 methods:
- def add(data: List[RowProcessResult]): Unit
- def getUnique(nameProcess: String): DataFrame or List[RowProcessResult]
Method add(..) has been added data collection in hive table.
Method getUnique(nameProcess: String): DataFrame. Returns a DataFrame with all columns for the unique values of the "key" column. For each unique "key" value, the most recent date is selected.
PS.: My test class for create Hive Table:
def createHiveTable(implicit spark: SparkSession) {
val schema = "test_schema"
val table = "test_table"
val partitionName = "name_process"
val columnNames = "name_process" :: "id_session" :: "time_write" :: "key" :: "value" :: Nil
spark.sql(s"CREATE DATABASE IF NOT EXISTS test_db")
//val createTableSql = s"CREATE TABLE IF NOT EXISTS $schema.$table ($columnNames) PARTITIONED BY $partitionName STORED AS parquet"
val path = new File(".").getAbsolutePath "/src/test/data-lineage/test_data_journal.csv"
val df = spark.read.option("delimiter", ",")
.option("header", true)
.csv(path)
df.show()
df.write.mode(SaveMode.Append).partitionBy(partitionName).format("parquet").saveAsTable(s"test_db.$table")
}
CodePudding user response:
It's been a long time. And i leave my decision this.
import spark.implicits._
val schema = "test_db"
val table = "test_table"
val df = spark.read.table(s"$schema.$table").filter(col("name_process") === processName).persist
def getLastSession: Dataset[Row] = {
val lastSessionId = df.select(max(struct(col("time_write"), col("id_session")))("id_session"))
.first.getString(0)
val dfByLastSession = df.filter(col("id_session") === lastSessionId)
dfByLastSession.show()
dfByLastSession
}
def add(listRows: Seq[RowProcessResult]) = {
val df = listRows.toDF().withColumn("name_process", lit(processName))
df.show()
addDfToTable(df)
}
def add(nameProcess: String, idSession: String, timeWrite: String, key: String, value: String) = {
val df = RowProcessResult(idSession, timeWrite, key, value) :: Nil toDF()
addDfToTable(df)
}
def getSessionsByProcess(externalProcessName: String) = {
spark.read.table(s"$schema.$table").filter(col("name_process") === externalProcessName)
}
def getSession(idSession: String, processName: String = this.processName) = {
if (processName.equals(this.processName))
df.filter(col("id_session") === idSession)
else
getSessionsByProcess(processName).filter(col("id_session") === idSession)
}
def getUnique = df.sort(col("time_write").desc).dropDuplicates("key")
def addDfToTable(df: DataFrame) =
df.write.mode(SaveMode.Append).insertInto(s"$schema.$table")
def getFullDf = df
def getCurrentTime = TimeStamp.getCurrentTime
def convertTime(time: Long): String = TimeStamp.getNtpTime(time).getDate.toString
}
I can get tolerable solution. This is not bad. Thank you and Happy New Years!! =)