I've been trying to write my own k-mean algorithm for the past couple of days, but I have hit a roadblock. When ever I try to find the average location of the points in a cluster to move the centroid, I get a zero division error(Note: this doesn't happen when k = 2, and only happens sometimes when k = 3, but always happens when k >= 4). I tried to fix this by making sure each centroid starts off at one of the points in the dataset, so that it always has at least one point in its cluster, but it hasn't worked. I've also rearranged counters and such, but again, it did not work. I have run out of ideas and am not sure why this error still happens. I'm pretty sure the problem is coming from one of these functions(edit: added all of code and full error message):
import random
import math
import matplotlib.pyplot as plt
class Kmeans:
def __init__(self, K, dataset, centroids, sorting):
self.K = K
self.dataset = dataset
self.centroids = centroids
self.sorting = sorting
def initializeCentroids(self):
usedPoints = [random.choice(data_set)]
self.centroids = []
for q in range(self.K):
pointSelected = False
while not pointSelected:
m = random.choice(data_set)
print(m)
print(usedPoints)
distance = math.sqrt(abs(((m[0] - usedPoints[len(usedPoints) - 1][0]) ** 2) (m[1] - usedPoints[len(usedPoints) - 1][1]) ** 2))
if usedPoints.count(m) == 0 and distance > 50:
self.centroids.append(list(m))
usedPoints.append(m)
pointSelected = True
return self.centroids
def calcDistance(self):
self.sorting = []
for w in self.dataset:
distances = []
counter = -1
for centr in self.centroids:
counter = 1
distances.append(math.sqrt(abs((((w[0] - centr[0]) ** 2) (w[1] - centr[1]) ** 2))))
for x in range(len(distances)):
if len(distances) > 1:
print(distances)
if distances[0] > distances[1]:
distances.pop(0)
else:
distances.pop(1)
counter -= 1
print(counter)
self.sorting.insert(0, [w, counter, distances[0]])
return self.sorting
# not done
def find_ME(self):
counter2 = 0
for r in self.centroids:
for t in self.sorting:
nums = []
if t[1] == counter2:
nums.append(t[2])
population = len(nums)
error = sum(nums) / population
def reassignCentroids(self):
counter3 = 0
for r in self.centroids:
positionsX = []
positionsY = []
for t in self.sorting:
if t[1] == counter3:
positionsX.append(t[0][0])
positionsY.append(t[0][1])
population = len(positionsY)
print(population)
print(self.sorting)
r[0] = sum(positionsX) / population
r[1] = sum(positionsY) / population
counter3 = 1
return self.centroids
def checkSimilar(self, prevList):
list1 = []
list2 = []
for u in prevList:
list1.append(u[1])
for i in self.sorting:
list2.append(i[1])
print(i)
if list2 == list1:
return True
else:
return False
k = 3
data_set = [(1, 1), (1, 2), (1, 3), (2, 3), (50, 52), (48, 50), (47, 60), (112, 90), (120, 100), (108, 130), (102, 121), (43, 51), (0, 1)]
attempt = Kmeans(k, data_set, [], [])
attempt.initializeCentroids()
xvals = []
yvals = []
sortCompare = []
maxIterations = 100000
# plots
for p in data_set:
xvals.append(p[0])
yvals.append(p[1])
running = True
zeroError = True
while running:
attempt.calcDistance()
sortCompare = attempt.sorting
print(sortCompare, "thisss")
attempt.reassignCentroids()
attempt.calcDistance()
attempt.reassignCentroids()
boolVal = attempt.checkSimilar(sortCompare)
if boolVal or maxIterations <= 0:
xs = []
ys = []
for y in attempt.centroids:
xs.append(y[0])
ys.append(y[1])
plt.scatter(xs, ys)
running = False
else:
sortCompare = []
maxIterations -= 1
print(attempt.sorting)
print(attempt.centroids)
plt.scatter(xvals, yvals)
plt.show()
Full error: Traceback (most recent call last): File "C:/Users/Jack Cramer/PycharmProjects/kmeans/main.py", line 117, in attempt.reassignCentroids() File "C:/Users/Jack Cramer/PycharmProjects/kmeans/main.py", line 73, in reassignCentroids r[0] = sum(positionsX) / population ZeroDivisionError: division by zero
If you know why this is happening please let me know, thanks for any advice.
CodePudding user response:
As @thierry-lathuille pointed out, the error occurs in reassignCentroids when you divide by population which is zero. population is set to be the length of positionsY, so we need to see which scenarios cause positionsY to have no elements.
positionsY has its values appended inside a loop over the values t in self.sorting. A value is only appended if counter3 (which ranges from 0 to K-1) matches t[1]. So if there is a value of counter3 for which none of the t[1] values are equal, we'll get the error. To help debug, I've added some print statements to the loop
print(f"{counter3=}")
for t in self.sorting:
print(f"{t[1]=}")
if t[1] == counter3:
positionsX.append(t[0][0])
positionsY.append(t[0][1])
Running this several times with k=2, I see that t[1] is either 0 or 1, which won't crash, as you see. However, going up to k=3, sometimes I get t[1] equal to 0, 1, or 2, but other times it only equals 0 or 1. This means there will be no matches, and you'll divide by zero. Going up to k=4, we should get t[1] equal to 0, 1, 2, or 3, but I'm not seeing any 3's after many restarts.
From context, I'm guessing that t[1] represents the cluster that a given data point is closest to. From your inputs, it appears by eye that there are three clusters of points
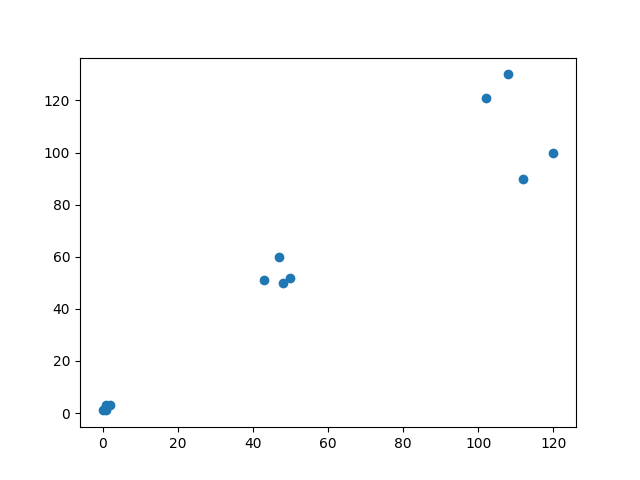 So your code naturally has three of the predicted clusters trend towards the places they should be, so if you're trying to predict 4 clusters, you'll always crash. If you're only trying to predict 3 clusters, you might get unlucky and one of your predicted clusters isn't the closest to any point. It wouldn't surprise me if even
So your code naturally has three of the predicted clusters trend towards the places they should be, so if you're trying to predict 4 clusters, you'll always crash. If you're only trying to predict 3 clusters, you might get unlucky and one of your predicted clusters isn't the closest to any point. It wouldn't surprise me if even k=2 errored out for certain initializations, but it must be rare in practice.
I think you need to first ask yourself what behavior you want to see when k is higher than the real number of clusters. And second you need to determine how to update a cluster's location when none of the data points are closest to it. A quick workaround would be to do nothing if population == 0, though that may not give the behavior you want.