I'm trying to use "for loop" to write a function extracting the data of one column from 2 csv.files, and work out the mean of these data. I'm wondering why the output of for loop need to be assigned as a empty vector c() to make the function work? I printed the sub-output for "foor loop" tring to figure out the reason. when I tried to exclude means<-c(), I got unexpected 1,2,3,4,5,6 for "means" from each time of loop. Could anyone kindly do a explanation for my confusion? Thank you very much.
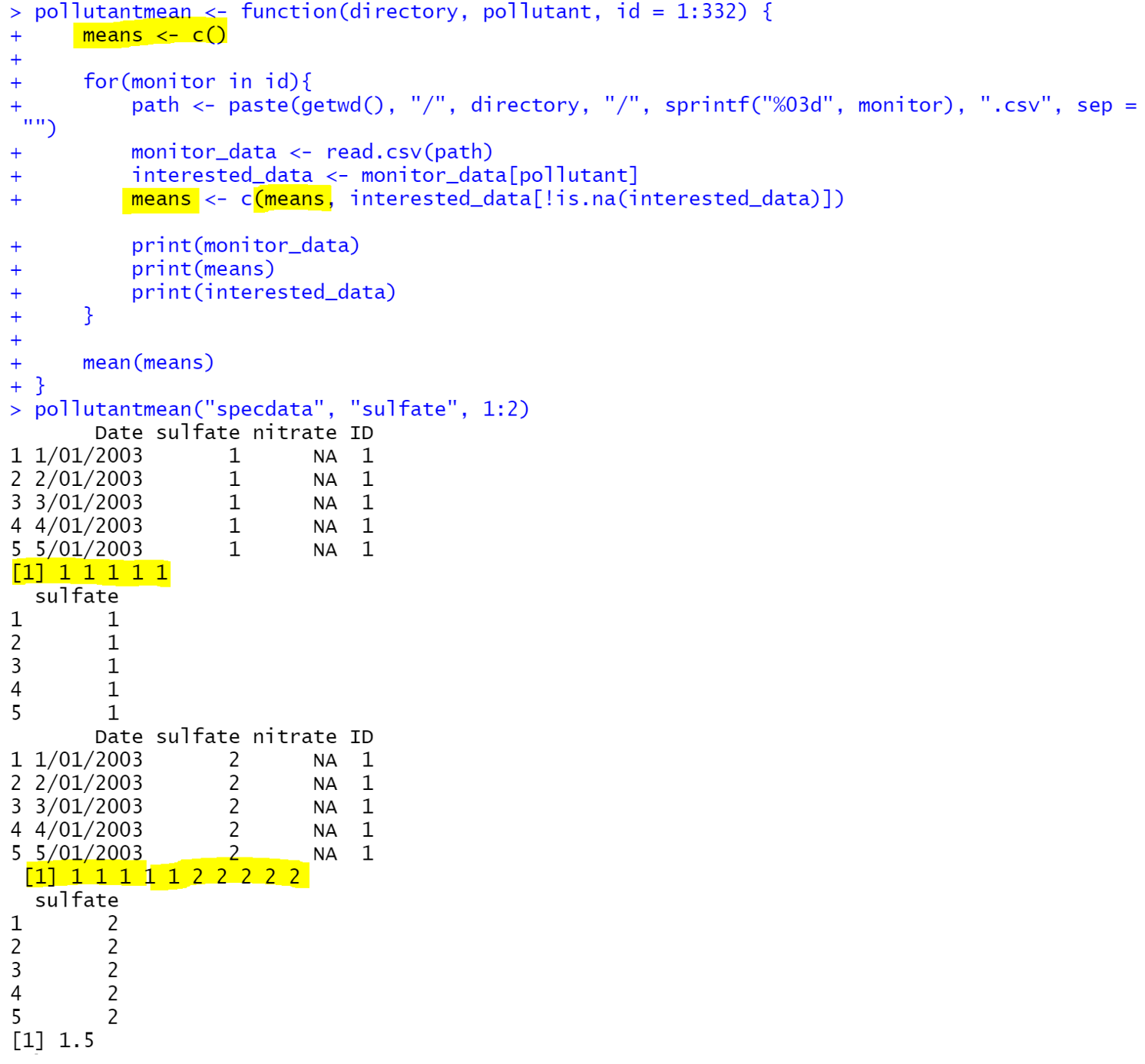
pollutantmean <- function(directory, pollutant, id = 1:332) {
means<-c()
for(monitor in id){
path <- paste(getwd(), "/", directory, "/", sprintf("d", monitor), ".csv", sep = "")
monitor_data <- read.csv(path)
interested_data <- monitor_data[pollutant]
means <- c(means, interested_data[!is.na(interested_data)])
print(monitor_data)
print(means)
print(interested_data)
}
mean(means)
}
pollutantmean("specdata", "sulfate", 1:2)
correct output with assigning means<-c()
wrong output without means<-c() before "for loop"

I think I found the essence of the qusetion which is I don't understand the logic behind:
> x=c(x,1)
> x
>[1] 9 1
> x=c()
> x=c(x,1)
> x
>[1] 1
It can represent one of the for loop, like the first round of the loop. I'm confused about how the value of x being assigned during each process for the upper two runs, why the first one gives the output of 9,1 but the second one gives the expected result? is anyone able to explain the what happens behind those two runs? Really grateful if anyone could answer it.
CodePudding user response:
In the case that doesn't work, you still have the line
means <- c(means, interested_data[!is.na(interested_data)])
that refers to means on the right hand side. If you didn't set means <- c(), then you'll get different results depending on whatever happened to be stored in that variable before executing this code. If there's no such variable, you'll get an error.
By the way, this isn't a great way to write R code, even with the means <- c() line. The problem is that every time you execute the line above you need to make a slightly longer vector to hold means. In your case you don't know how many values you'll be adding, so it's excusable, but in the more common case where you will always be adding one more entry, it's a lot more efficient to set up the result vector to the right length in advance and assign values using something like
means[i] <- newValue