I was wondering if it were possible to merge two datasets if the values were in a certain range of each other.
For example, If I want to join on zip codes, then an exact match isn't required and the join takes place if the left table zip code is within a range of 15 from the right table zip code.
Here is some example data and a diagram to make this clear.
# Create sample dataframe
data1 = [[10001, 'NY'], [10007, 'NY'], [10013, 'NY'], [90011, 'CA'], [91331, 'CA'], [90650, 'CA']]
data2 = [[10003, 'NY', 1200], [10008, 'NY', 1460], [10010, 'NY', 1900], [90011, 'CA', 850], [91315, 'CA', 1700], [90645, 'CA',2300]]
df_left = pd.DataFrame(data1, columns = ['Zip', 'State'])
df_right = pd.DataFrame(data2, columns = ['Zip', 'State', 'Average_Rent'])
print(df_left.head())
print(df_right.head())
# Merge
df_merge = df_left.merge(df_right, left_on='Zip', right_on = 'Zip', how='left')
print(df_merge)
# Want to merge if within a 5 zipcode radius. If two zips nearby, then choose the first observation.
data3 = [[10001, 'NY', 10003, 12000], [10007, 'NY', 10008, 1460], [10007, 'NY', 10010, 1900], [10013, 'NY', 'NaN', 'NaN'],
[90011, 'CA', 90011, 850], [91331, 'CA', 'NaN', 'NaN'], [90650, 'CA', 90645, 2300]]
df_want = pd.DataFrame(data3, columns = ['Zip_left', 'State', 'Zip_right', 'Rent'])
df_want.head(6)
The result of this is shown below:
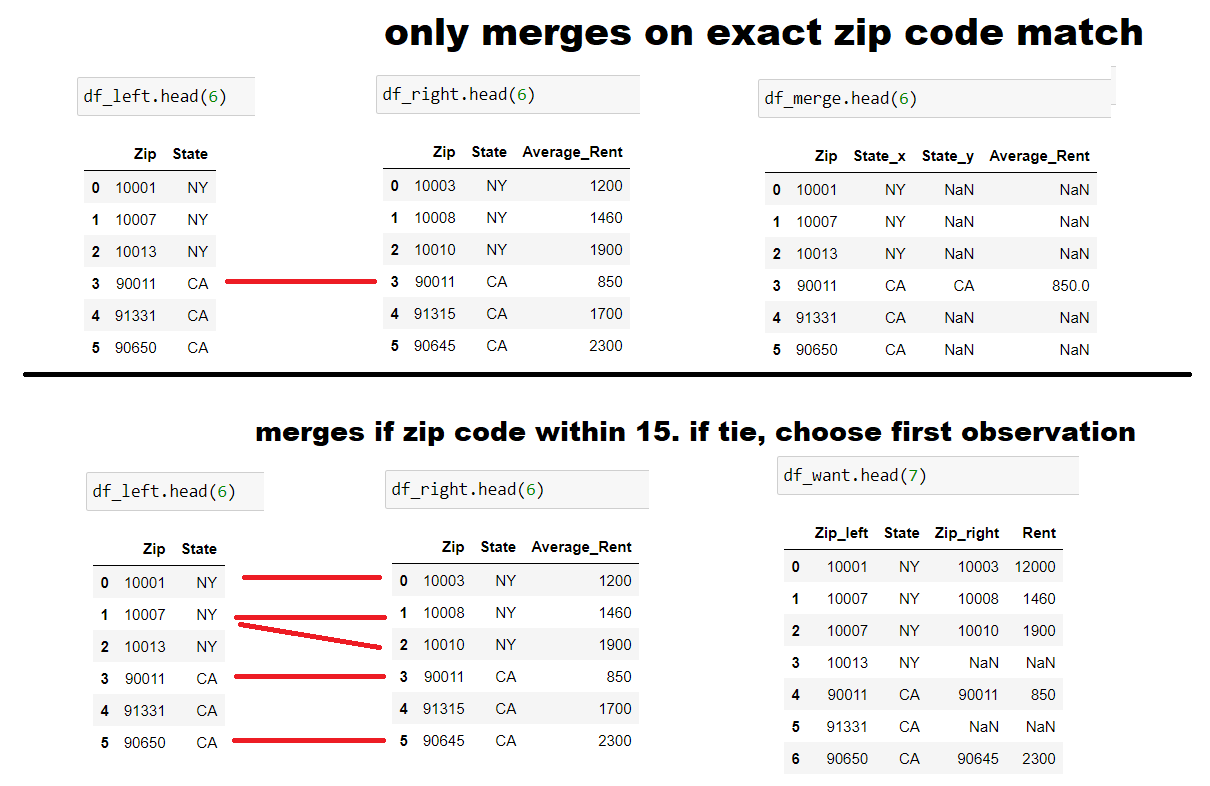
A traditional left join will leave me with the top result, whereas the result I am after is shown in the bottom (not concerned about what columns are output, I just input them on the spot).
The main rule I want to enforce is the interval merge. For the tie-breaker this example chooses the first one, but even if the zip code 10010 from the right table gets matched twice: once to 10007 and once to 10013, that's not an issue. Quite frankly the tie-breaker rule doesn't bother me, as long as at least one merge is made.
CodePudding user response:
Since pandas 1.2.0., you can cross merge, which creates the cartesian product from the two DataFrames. So cross merge and filter the columns where the states match. Then find the absolute difference between the zip codes and use it to identify the rows where the distance is the closest for each "Zip_left". Finally, mask the rows where the difference is greater than 15 (even if the closest), so we fill them with NaN:
merged = df_left.merge(df_right, how='cross', suffixes=('_left', '_right'))
merged = merged[merged['State_left']==merged['State_right']]
merged['Diff'] = merged['Zip_left'].sub(merged['Zip_right']).abs()
merged = merged[merged.groupby('Zip_left')['Diff'].transform('min') == merged['Diff']]
cols = merged.columns[~merged.columns.str.endswith('left')]
merged[cols] = merged[cols].mask(merged['Diff']>15)
out = merged.drop(columns=['State_right','Diff']).rename(columns={'State_left':'State'}).reset_index(drop=True)
Output:
Zip_left State Zip_right Average_Rent
0 10001 NY 10003.0 1200.0
1 10007 NY 10008.0 1460.0
2 10013 NY 10010.0 1900.0
3 90011 CA 90011.0 850.0
4 91331 CA NaN NaN
5 90650 CA 90645.0 2300.0