I have a dataset like below:
Group Attributes S2SFlag
Age 1 to 5 Yes
Age 6 to 10 No
Channel DD No
Channel Agency Yes
Status Lapse Yes
Status Active Yes
Now I want to explode the values of the 'Age' group by the range defined in the attributes column while retaining other column values.
The expected output is as below:
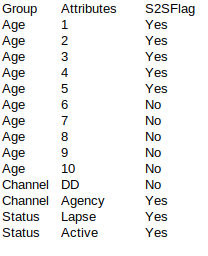
Attempt so far:
df1 = pd.read_csv('')
df1 = df1[df1['Group'] == 'Age']
attrList = df1['Attributes'].tolist()
for i in attrList:
start = i.split(" to ")[0]
end = i.split(" to ")[1]
for j in range(int(start), int(end) 1):
df1['Attributes'] = str(j)
It is giving me output as below:
Group Attributes S2SFlag
0 Age 10 Yes
1 Age 10 No
CodePudding user response:
You can use a custom function to replace the string with range, then explode:
import re
def to_range(s):
m = re.match('(\d ) to (\d )$', s)
return range(int(m.group(1)), int(m.group(2)) 1) if m else s
(df.assign(Attributes=[to_range(s) for s in df['Attributes']])
.explode('Attributes')
)
output:
Group Attributes S2SFlag
0 Age 1 Yes
0 Age 2 Yes
0 Age 3 Yes
0 Age 4 Yes
0 Age 5 Yes
1 Age 6 No
1 Age 7 No
1 Age 8 No
1 Age 9 No
1 Age 10 No
2 Channel DD No
3 Channel Agency Yes
4 Status Lapse Yes
5 Status Active Yes