How to sort or group by dataframe by specific values from multiple columns with Pandas?
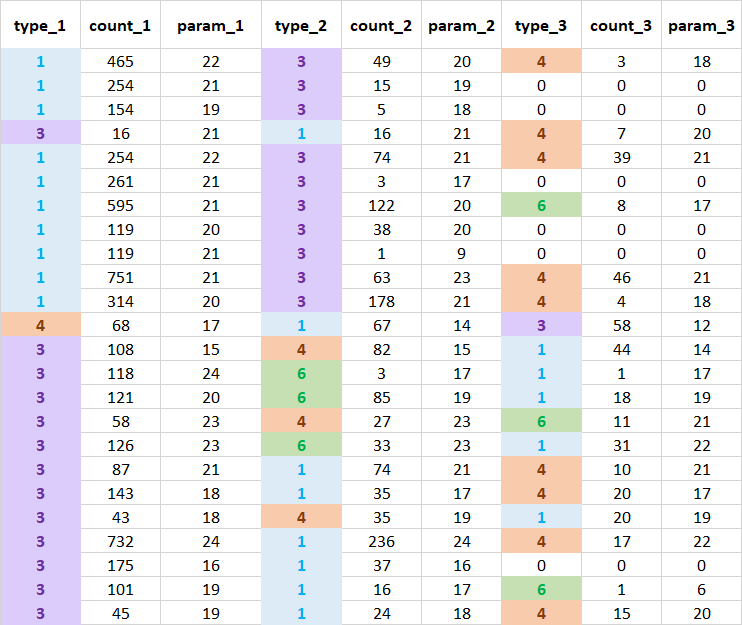
The dataframe that I am working with looks like below. I have 3 type columns with corresponding parameters count and param. For each type accordingly count and param column. I need to sort them based on type value, so the result would be new columns with its parameters for type = '1', type = '3', type = '3' and type = '6'.
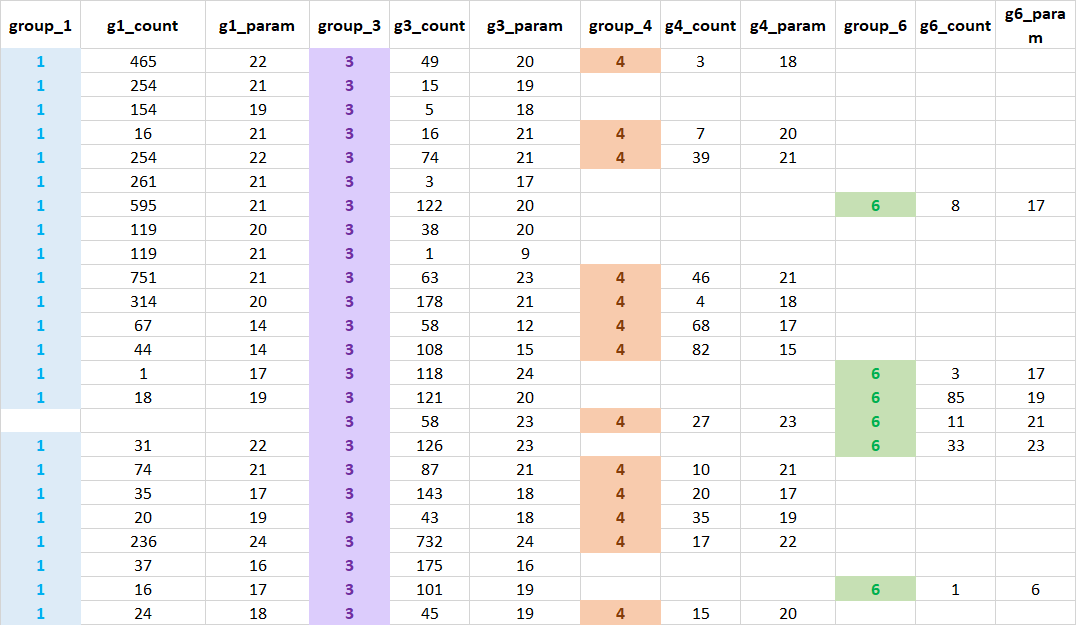
The desired result looks like this:
What I tried is this, however, I really not sure that this will do what I want, also with I would sort only type columns and not count and param as well:
import pandas as pd
dataframe = pd.read_csv(r'W:\...file.csv')
type_col = 1
new_column = 'group_1'
dataframe.loc[dataframe[type_1'] == type_col, group_1] = type_col
dataframe.loc[dataframe['type_2'] == type_col, group_1] = type_col
dataframe.loc[dataframe['type_3'] == type_col, group_1] = type_col
Here is the print output of dataframe.head(20):
print(dataframe.head(20).to_dict('list'))
{'type_1': [1, 1, 1, 3, 1, 1, 1, 1, 1, 1, 1, 4, 3, 3, 3, 3, 3, 3, 3, 3], 'count_1': [465, 254, 154, 16, 254, 261, 595, 119, 119, 751, 314, 68, 108, 118, 121, 58, 126, 87, 143, 43], 'param_1': [22, 21, 19, 21, 22, 21, 21, 20, 21, 21, 20, 17, 15, 24, 20, 23, 23, 21, 18, 18], 'type_2': [3, 3, 3, 1, 3, 3, 3, 3, 3, 3, 3, 1, 4, 6, 6, 4, 6, 1, 1, 4], 'count_2': [49, 15, 5, 16, 74, 3, 122, 38, 1, 63, 178, 67, 82, 3, 85, 27, 33, 74, 35, 35], 'param_2': [20, 19, 18, 21, 21, 17, 20, 20, 9, 23, 21, 14, 15, 17, 19, 23, 23, 21, 17, 19], 'type_3': [4, 0, 0, 4, 4, 0, 6, 0, 0, 4, 4, 3, 1, 1, 1, 6, 1, 4, 4, 1], 'count_3': [3, 0, 0, 7, 39, 0, 8, 0, 0, 46, 4, 58, 44, 1, 18, 11, 31, 10, 20, 20], 'param_3': [18, 0, 0, 20, 21, 0, 17, 0, 0, 21, 18, 12, 14, 17, 19, 21, 22, 21, 17, 19]}
And the full dataframe: print(dataframe)
type_1 count_1 param_1 type_2 count_2 param_2 type_3 count_3 \
0 1 465 22 3 49 20 4 3
1 1 254 21 3 15 19 0 0
2 1 154 19 3 5 18 0 0
3 3 16 21 1 16 21 4 7
4 1 254 22 3 74 21 4 39
5 1 261 21 3 3 17 0 0
6 1 595 21 3 122 20 6 8
7 1 119 20 3 38 20 0 0
8 1 119 21 3 1 9 0 0
9 1 751 21 3 63 23 4 46
10 1 314 20 3 178 21 4 4
11 4 68 17 1 67 14 3 58
12 3 108 15 4 82 15 1 44
13 3 118 24 6 3 17 1 1
14 3 121 20 6 85 19 1 18
15 3 58 23 4 27 23 6 11
16 3 126 23 6 33 23 1 31
17 3 87 21 1 74 21 4 10
18 3 143 18 1 35 17 4 20
19 3 43 18 4 35 19 1 20
20 3 732 24 1 236 24 4 17
21 3 175 16 1 37 16 0 0
22 3 101 19 1 16 17 6 1
23 3 45 19 1 24 18 4 15
param_3
0 18
1 0
2 0
3 20
4 21
5 0
6 17
7 0
8 0
9 21
10 18
11 12
12 14
13 17
14 19
15 21
16 22
17 21
18 17
19 19
20 22
21 0
22 6
23 20
CodePudding user response:
Use wide_to_long for reshape first, then create helper column type1 used for groups by add to MultiIndex in DataFrame.set_index, remove second level by DataFrame.droplevel and reshape by DataFrame.unstack, last sorting by second level and flatten MultiIndex in columns:
df = (pd.wide_to_long(df.reset_index(),
stubnames=['type','count','param'],
i = 'index',
j='tmp',
sep='_')
.assign(type1 = lambda x: x['type'])
.query("type != 0")
.set_index('type1', append=True)
.droplevel(1)
.unstack()
.sort_index(level=1, axis=1, sort_remaining=False)
)
df.columns = [f'group_{b}' if a == 'type' else f'g{b}_{a}' for a, b in df.columns]
print (df.head(10))
group_1 g1_count g1_param group_3 g3_count g3_param group_4 \
index
0 1.0 465.0 22.0 3.0 49.0 20.0 4.0
1 1.0 254.0 21.0 3.0 15.0 19.0 NaN
2 1.0 154.0 19.0 3.0 5.0 18.0 NaN
3 1.0 16.0 21.0 3.0 16.0 21.0 4.0
4 1.0 254.0 22.0 3.0 74.0 21.0 4.0
5 1.0 261.0 21.0 3.0 3.0 17.0 NaN
6 1.0 595.0 21.0 3.0 122.0 20.0 NaN
7 1.0 119.0 20.0 3.0 38.0 20.0 NaN
8 1.0 119.0 21.0 3.0 1.0 9.0 NaN
9 1.0 751.0 21.0 3.0 63.0 23.0 4.0
g4_count g4_param group_6 g6_count g6_param
index
0 3.0 18.0 NaN NaN NaN
1 NaN NaN NaN NaN NaN
2 NaN NaN NaN NaN NaN
3 7.0 20.0 NaN NaN NaN
4 39.0 21.0 NaN NaN NaN
5 NaN NaN NaN NaN NaN
6 NaN NaN 6.0 8.0 17.0
7 NaN NaN NaN NaN NaN
8 NaN NaN NaN NaN NaN
9 46.0 21.0 NaN NaN NaN
EDIT:
d = {'type_1': [3, 1, 1, 3, 1, 1, 1, 1, 1, 1, 1, 4, 3, 3, 3, 3, 3, 3, 3, 3], 'count_1': [465, 254, 154, 16, 254, 261, 595, 119, 119, 751, 314, 68, 108, 118, 121, 58, 126, 87, 143, 43], 'param_1': [22, 21, 19, 21, 22, 21, 21, 20, 21, 21, 20, 17, 15, 24, 20, 23, 23, 21, 18, 18], 'type_2': [3, 3, 3, 1, 3, 3, 3, 3, 3, 3, 3, 1, 4, 6, 6, 4, 6, 1, 1, 4], 'count_2': [49, 15, 5, 16, 74, 3, 122, 38, 1, 63, 178, 67, 82, 3, 85, 27, 33, 74, 35, 35], 'param_2': [20, 19, 18, 21, 21, 17, 20, 20, 9, 23, 21, 14, 15, 17, 19, 23, 23, 21, 17, 19], 'type_3': [4, 0, 0, 4, 4, 0, 6, 0, 0, 4, 4, 3, 1, 1, 1, 6, 1, 4, 4, 1], 'count_3': [3, 0, 0, 7, 39, 0, 8, 0, 0, 46, 4, 58, 44, 1, 18, 11, 31, 10, 20, 20], 'param_3': [18, 0, 0, 20, 21, 0, 17, 0, 0, 21, 18, 12, 14, 17, 19, 21, 22, 21, 17, 19]}
df = pd.DataFrame(d)
df = (pd.wide_to_long(df.reset_index(),
stubnames=['type','count','param'],
i = 'index',
j='tmp',
sep='_')
.assign(type1 = lambda x: x['type'])
.set_index('type1', append=True)
.droplevel(1)
.reset_index())
df = df[df.duplicated(['index','type'], keep=False)]
print (df)
index type1 type count param
0 0 3 3 465 22
20 0 3 3 49 20