My model consists of an Embedding layer and a SimpleRNN layer. I have obtained the hidden states at all steps with model.predict, and plotted them against the steps. I find that the hidden states converge to zero but I am not sure if I can infer anything from that. Therefore plotting their gradients with respect to the model inputs might provide me some further insights. I would like some help with obtaining these gradients.
My model:
batch_size = 9600 # batch size can take a smaller value, e.g. 100
inp= Input(batch_shape= (batch_size, input_length), name= 'input')
emb_out= Embedding(input_dim, output_dim, input_length= input_length,
weights= [Emat], trainable= False, name= 'embedding')(inp)
rnn= SimpleRNN(200, return_sequences= True, return_state= False, stateful= True,
batch_size= (batch_size, input_length, 100), name= 'simpleRNN')
h0 = tf.random.uniform((batch_size, 200))
rnn_allstates = rnn(emb_out, initial_state=h0)
print(rnn_allstates.shape) # (9600, 1403, 200)
model_rnn = Model(inputs=inp, outputs= rnn_allstates, name= 'model_rnn')
model_rnn.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc'])
model_rnn.summary()
>>>
Layer (type) Output Shape Param #
=================================================================
input (InputLayer) [(9600, 1403)] 0
_________________________________________________________________
embedding (Embedding) (9600, 1403, 100) 4348900
_________________________________________________________________
simpleRNN (SimpleRNN) (9600, 1403, 200) 60200
=================================================================
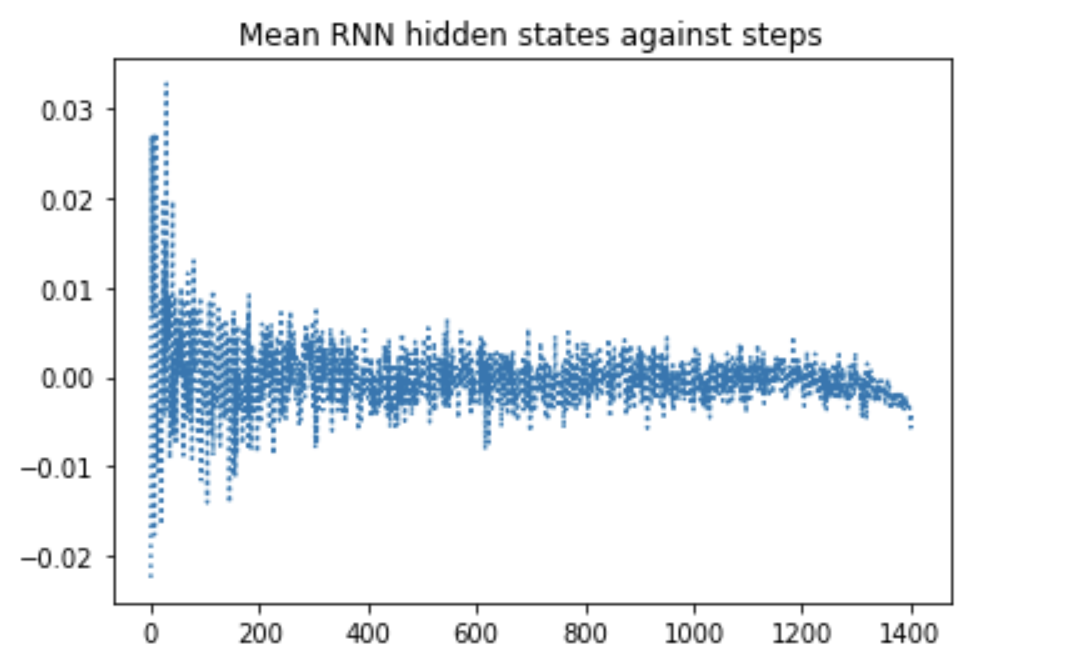
Obtaining the hidden states:
rnn_ht = model_rnn.predict(xtr_pad) # xtr_pad.shape = (9600,1403)
rnn_ht_red= np.mean(rnn_ht, 2)
rnn_ht_red= np.mean(rnn_ht_red,0)
steps= [t for t in range(1403)]
plt.plot(steps, rnn_ht_red, linestyle= 'dotted')
Attempt to obtain gradients:
sess= k.get_session()
# The hidden states tf.Variable shaped (n_samples = 9600, n_steps = 1403, n_units = 200):
states_var= model_rnn.output
# A list of hidden states variable for all time steps, aggregated over samples and RNN units:
ht_vars= [states_var[:, t, :] for t in range(1403)] # each item in list has shape (9600, 200)
ht_vars_agg= [tf.reduce_mean(ht,[0,1]) for ht in ht_vars] # each item in list has shape (), because I wish to obtain a SINGLE gradient value at each time step.
# Create gradient function and feed data:
dhtdx_vars= [k.gradients(ht, model_rnn.input) for ht in ht_vars_agg]
dhtdx= [sess.run(pd, feed_dict={model_rnn.input: xtr_pad} ) for pd in dhtdx_vars ]
The following error points to the last line above
TypeError: Fetch argument None has invalid type <class 'NoneType'>
Every backend gradient item in dhtdx_vars is [None]. When I remove the aggregation line the same error still persists.
An attempt with gradient tape also returns None Error in the computed gradient.
with tf.GradientTape() as tape:
x= model_rnn.input
ht = model_rnn(x)
grad = tape.gradient(ht, model_rnn.input)
Thanks in advance for any help.
CodePudding user response:
The problem is tf.GradientTape() doesn't propagate the gradients through integer inputs. That is probably the reason you are getting None gradients. What you can do is calculate the gradients with respect to the output of the Embedding layer like this:
import tensorflow as tf
input_length = 1403
inp= tf.keras.layers.Input(shape= (input_length,))
emb_out= tf.keras.layers.Embedding(500, 100, input_length= input_length, trainable= False)(inp)
rnn_out = tf.keras.layers.SimpleRNN(200, return_sequences = True)(emb_out)
model = tf.keras.Model(inputs=inp, outputs=rnn_out)
model.summary()
xte_pad = tf.random.uniform((10, 1403), maxval=500, dtype=tf.int32)
y = tf.random.normal((10, 1403, 200))
ds = tf.data.Dataset.from_tensor_slices((xte_pad, y)).batch(5)
embedding_layer = model.layers[1]
rnn_layer = model.layers[2]
epochs = 1
for epoch in range(epochs):
for step, (x_batch_train, y_batch_train) in enumerate(ds):
with tf.GradientTape() as tape:
embedded_x = embedding_layer(x_batch_train)
tape.watch(embedded_x)
y = rnn_layer(embedded_x)
grads = tape.gradient(y, embedded_x)
tf.print(grads.shape)
Model: "model_10"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_13 (InputLayer) [(None, 1403)] 0
embedding_12 (Embedding) (None, 1403, 100) 50000
simple_rnn_12 (SimpleRNN) (None, 1403, 200) 60200
=================================================================
Total params: 110,200
Trainable params: 60,200
Non-trainable params: 50,000
_________________________________________________________________
TensorShape([5, 1403, 100])
TensorShape([5, 1403, 100])