I have a pandas dataframe that contains 2 columns: Predicted time & Actual times. I would like a third column that contains true or false values. In other words, if for every predicted time row the time matches one of the actual times in that same row OR the predicted time lies in-between one of those actual times, then add a 'True' to the third column value. Else, add a 'False' in the row.
Any ideas where to begin? I assume this requires two things: datetime module for comparing & iterating through every row to produce the newly written row value?
Current dataframe:
;Predicted time;Actual times
0;[2017-09-09 06:53:37, 2017-09-09 06:53:46];[2017-09-09 06:54:11, 2017-09-09 06:54:21,] [2017-09-09 06:54:29, 2017-09-09 06:55:14], [2017-09-09 06:55:30, 2017-09-09 06:55:51]]
1;[2017-09-09 06:54:19, 2017-09-09 06:54:43];[2017-09-09 06:54:11, 2017-09-09 06:54:21, 2017-09-09 06:54:29, 2017-09-09 06:55:14, 2017-09-09 06:55:30, 2017-09-09 06:55:51]
2;[2017-09-09 06:54:44, 2017-09-09 06:54:48];[2017-09-09 06:54:11, 2017-09-09 06:54:21,] [2017-09-09 06:54:29, 2017-09-09 06:55:14], [2017-09-09 06:55:30, 2017-09-09 06:55:51]]
Desired output
;Predicted time;Actual times;True or False
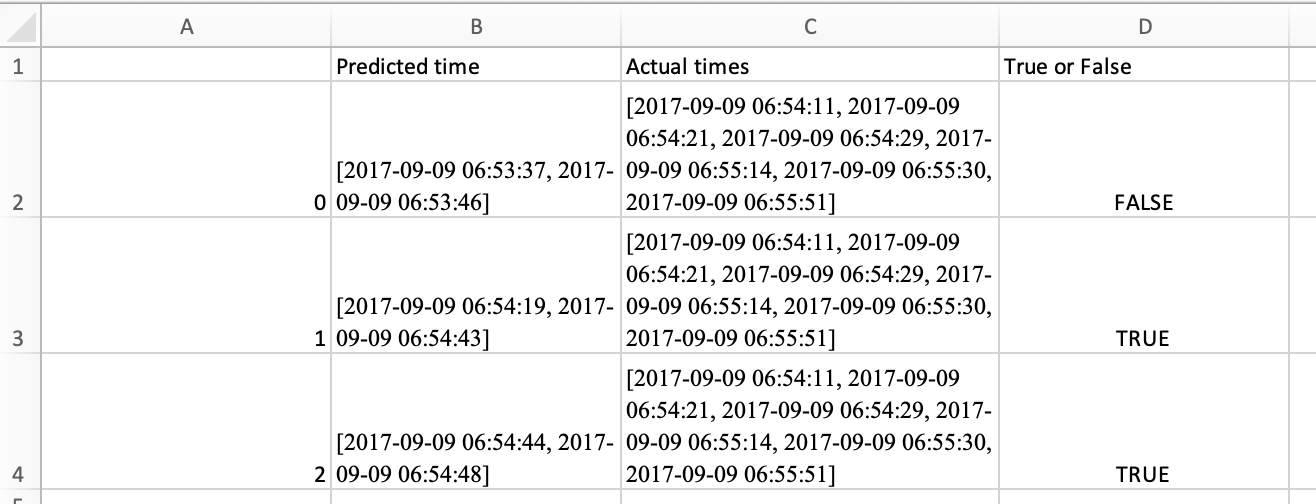
0;[2017-09-09 06:53:37, 2017-09-09 06:53:46];[2017-09-09 06:54:11, 2017-09-09 06:54:21,] [2017-09-09 06:54:29, 2017-09-09 06:55:14], [2017-09-09 06:55:30, 2017-09-09 06:55:51]];FALSE
1;[2017-09-09 06:54:19, 2017-09-09 06:54:43];[2017-09-09 06:54:11, 2017-09-09 06:54:21, 2017-09-09 06:54:29, 2017-09-09 06:55:14, 2017-09-09 06:55:30, 2017-09-09 06:55:51];TRUE
2;[2017-09-09 06:54:44, 2017-09-09 06:54:48];[2017-09-09 06:54:11, 2017-09-09 06:54:21,] [2017-09-09 06:54:29, 2017-09-09 06:55:14], [2017-09-09 06:55:30, 2017-09-09 06:55:51]];TRUE
I have also attached an image to show the desired output more clearly.
CodePudding user response:
Use list comprehension with test values between with any for test at least one True:
#for converting to datetimes, in Actual times was removed nested lists
f = lambda x: pd.to_datetime(x.strip('[]').split(', ')).tolist()
df[['Actual times', 'Predicted time']] = df[['Actual times', 'Predicted time']].applymap(f)
df['True or False'] = [any((s < y) & (e > y) for y in x)
for (s, e), x in zip(df['Predicted time'], df['Actual times'])]
print (df)
Predicted time \
0 [2017-09-09 06:53:37, 2017-09-09 06:53:46]
1 [2017-09-09 06:54:19, 2017-09-09 06:54:43]
2 [2017-09-09 06:54:44, 2017-09-09 06:54:48]
Actual times True or False
0 [2017-09-09 06:54:11, 2017-09-09 06:54:21, 201... False
1 [2017-09-09 06:54:11, 2017-09-09 06:54:21, 201... True
2 [2017-09-09 06:54:11, 2017-09-09 06:54:21, 201... False
CodePudding user response:
Most of the work in the function below is to convert the strings in your dataframe to a collection of datetime objects that can be used for comparison -
def pred_intersects_act(row):
#Convert predicted times to list of datetime objects
predicted_time = re.sub(r'\[|\]', '', row['predicted_time'])
predicted_time = re.sub(r',\ *', ',', predicted_time)
pt_list = predicted_time.split(',')
pt_list = [dt.strptime(_, '%Y-%m-%d %H:%M:%S') for _ in pt_list]
#Convert actual times to list of datetime objects
actual_times = re.sub(r'\[|\]', '', row['actual_times'])
actual_times = re.sub(r',\ *', ',', actual_times)
at_list = actual_times.split(',')
at_list = [dt.strptime(_, '%Y-%m-%d %H:%M:%S') for _ in at_list]
#pair up actual times and check for intersection
for pair in zip(at_list[:-1], at_list[1:]):
exact_match = any(_ in pair for _ in pt_list)
approx_match = any(bisect.bisect(pair, _) == 1 for _ in pt_list)
if exact_match or approx_match:
return True
return False
df.apply(pred_intersects_act, axis=1)
0 False
1 True
2 True
dtype: bool