To delete lines in a CSV file that have empty cells - I use the following code:
import pandas as pd
data = pd.read_csv("./test_1.csv", sep=";")
data.dropna()
data.dropna().to_csv("./test_2.csv", index=False, sep=";")
everything works fine, but I get a new CSV file with incorrect data:
what is highlighted in red squares
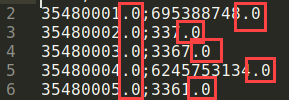
I get additional signs in the form of a dot and a zero .0.
Could you please tell me how do I get correct data without .0
Thank you very much!
CodePudding user response:
Pandas represents numeric NAs as NaNs and therefore casts all of your ints as floats (python int doesn't have a NaN value, but float does).
If you are sure that you removed all NAs, just cast your columns/dfs to int:
data = data.astype(int)
If you want to have integers and NAs, use pandas nullable integer types such as pd.Int64Dtype().
more on nullable integer types: https://pandas.pydata.org/pandas-docs/stable/user_guide/integer_na.html