I need some help regarding this OOM status of pods 137. I am kinda stuck here for 3 days now. I built a docker image of a flask application. I run the docker image, it was running fine with a memory usage of 2.7 GB.
I uploaded it to GKE with the following specification.

Workloads show "Does not have minimum availability"
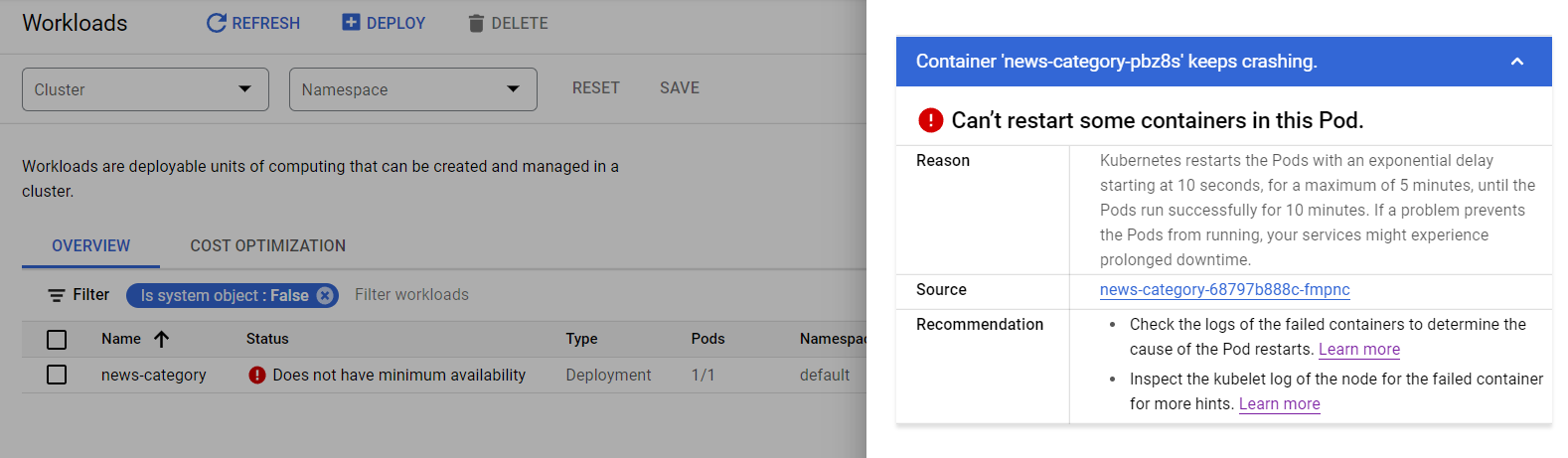
Checking that pod "news-category-68797b888c-fmpnc" shows CrashLoopBackError
Error "back-off 5m0s restarting failed container=news-category-pbz8s pod=news-category-68797b888c-fmpnc_default(d5b0fff8-3e35-4f14-8926-343e99195543): CrashLoopBackOff"
Checking the YAML file shows OOM killed 137.
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2022-02-17T16:07:36Z"
generateName: news-category-68797b888c-
labels:
app: news-category
pod-template-hash: 68797b888c
managedFields:
- apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
f:metadata:
f:generateName: {}
f:labels:
.: {}
f:app: {}
f:pod-template-hash: {}
f:ownerReferences:
.: {}
k:{"uid":"8d99448a-04f6-4651-a652-b1cc6d0ae4fc"}:
.: {}
f:apiVersion: {}
f:blockOwnerDeletion: {}
f:controller: {}
f:kind: {}
f:name: {}
f:uid: {}
f:spec:
f:containers:
k:{"name":"news-category-pbz8s"}:
.: {}
f:image: {}
f:imagePullPolicy: {}
f:name: {}
f:resources: {}
f:terminationMessagePath: {}
f:terminationMessagePolicy: {}
f:dnsPolicy: {}
f:enableServiceLinks: {}
f:restartPolicy: {}
f:schedulerName: {}
f:securityContext: {}
f:terminationGracePeriodSeconds: {}
manager: kube-controller-manager
operation: Update
time: "2022-02-17T16:07:36Z"
- apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
f:status:
f:conditions:
k:{"type":"ContainersReady"}:
.: {}
f:lastProbeTime: {}
f:lastTransitionTime: {}
f:message: {}
f:reason: {}
f:status: {}
f:type: {}
k:{"type":"Initialized"}:
.: {}
f:lastProbeTime: {}
f:lastTransitionTime: {}
f:status: {}
f:type: {}
k:{"type":"Ready"}:
.: {}
f:lastProbeTime: {}
f:lastTransitionTime: {}
f:message: {}
f:reason: {}
f:status: {}
f:type: {}
f:containerStatuses: {}
f:hostIP: {}
f:phase: {}
f:podIP: {}
f:podIPs:
.: {}
k:{"ip":"10.16.3.4"}:
.: {}
f:ip: {}
f:startTime: {}
manager: kubelet
operation: Update
time: "2022-02-17T16:55:18Z"
name: news-category-68797b888c-fmpnc
namespace: default
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: news-category-68797b888c
uid: 8d99448a-04f6-4651-a652-b1cc6d0ae4fc
resourceVersion: "25100"
uid: d5b0fff8-3e35-4f14-8926-343e99195543
spec:
containers:
- image: gcr.io/projectiris-327708/news_category:noConsoleDebug
imagePullPolicy: IfNotPresent
name: news-category-pbz8s
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-z2lbp
readOnly: true
dnsPolicy: ClusterFirst
enableServiceLinks: true
nodeName: gke-news-category-cluste-default-pool-42e1e905-ftzb
preemptionPolicy: PreemptLowerPriority
priority: 0
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: default
serviceAccountName: default
terminationGracePeriodSeconds: 30
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
volumes:
- name: kube-api-access-z2lbp
projected:
defaultMode: 420
sources:
- serviceAccountToken:
expirationSeconds: 3607
path: token
- configMap:
items:
- key: ca.crt
path: ca.crt
name: kube-root-ca.crt
- downwardAPI:
items:
- fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
path: namespace
status:
conditions:
- lastProbeTime: null
lastTransitionTime: "2022-02-17T16:07:37Z"
status: "True"
type: Initialized
- lastProbeTime: null
lastTransitionTime: "2022-02-17T16:55:18Z"
message: 'containers with unready status: [news-category-pbz8s]'
reason: ContainersNotReady
status: "False"
type: Ready
- lastProbeTime: null
lastTransitionTime: "2022-02-17T16:55:18Z"
message: 'containers with unready status: [news-category-pbz8s]'
reason: ContainersNotReady
status: "False"
type: ContainersReady
- lastProbeTime: null
lastTransitionTime: "2022-02-17T16:07:36Z"
status: "True"
type: PodScheduled
containerStatuses:
- containerID: containerd://a582af0248a330b7d4087916752bd941949387ed708f00b3aac6f91a6ef75e63
image: gcr.io/projectiris-327708/news_category:noConsoleDebug
imageID: gcr.io/projectiris-327708/news_category@sha256:c4b3385bd80eff2a0c0ec0df18c6a28948881e2a90dd1c642ec6960b63dd017a
lastState:
terminated:
containerID: containerd://a582af0248a330b7d4087916752bd941949387ed708f00b3aac6f91a6ef75e63
exitCode: 137
finishedAt: "2022-02-17T16:55:17Z"
reason: OOMKilled
startedAt: "2022-02-17T16:54:48Z"
name: news-category-pbz8s
ready: false
restartCount: 13
started: false
state:
waiting:
message: back-off 5m0s restarting failed container=news-category-pbz8s pod=news-category-68797b888c-fmpnc_default(d5b0fff8-3e35-4f14-8926-343e99195543)
reason: CrashLoopBackOff
hostIP: 10.160.0.42
phase: Running
podIP: 10.16.3.4
podIPs:
- ip: 10.16.3.4
qosClass: BestEffort
startTime: "2022-02-17T16:07:37Z"
My question is what to do and how to do to solve this. I tried to add resources to the YAML file in spec-
resources:
limits:
memory: 32Gi
requests:
memory: 16Gi
It also shows errors. How do I increase the memory of pods? And also if I increase memory it shows "Pod Unscheduled".
Someone plz give me an insight into clusters, nodes, and pods and how to solve this. Thank you.
CodePudding user response:
A Pod always runs on a Node and is the basic unit in a kubernetes engine. A Node is a worker machine in Kubernetes and may be either a virtual or a physical machine, depending on the cluster. A cluster is a set of nodes that run containerized applications.
Now coming back to your question on OOM issue. Mostly this occurs because your pods are trying to go beyond the memory that you have mentioned in your limits (in the YAML file). You can assume that your resource allocation ranges from your requests - limits in your case [16Gi - 32Gi]. Now should you assign more memory to solve this. Absolutely NOT! Thats not how the containerization or even any microservices concepts work. Read more about vertical scaling and horizontal scaling.
Now how you can avoid this problem. So lets assume that if your container runs a basic java spring boot application. Then you can try setting the jvm arguments like (-Xms , -Xms, -GCpolicies) etc., which are your standard configs for any java application and unless you specify it explicitly in a container environment, it will not work as it works in a local machine.
CodePudding user response:
The message back-off restarting failed container appears when you are facing a temporary resource overload, as a result of an activity spike. And the OOMKilled code 137 means that a container or pod was terminated because they used more memory than the one allowed. OOM stands for “Out Of Memory”.
So based on this information from your GKE configuration (Total of memory 16Gi ), I suggest review the total of memory limited configured in your GKE, you can confirm this issue with the following command: kubectl describe pod [name]
You will need to determine why Kubernetes decided to terminate the pod with the OOMKilled error, and adjust memory requests and limit values.
To review all the GKE metrics, you go to the Google console, then to the monitoring dashboard and select GKE. In this monitoring dashboard, you will find the statistics related to memory and CPU.
Also, it is important to review if the containers have enough resources to run your applications. You can follow this link to know the Kubernetes best practices.
GKE also has an interesting feature, which is autoscaling. It is very useful because it automatically resizes your GKE cluster based on the demands of your workloads. You can find more information in this link.