To aggregate the data, I use the code:
import pandas
df = pandas.read_csv("./input_file.csv", delimiter=";", low_memory=False)
df.head()
count_severity = df.groupby("B")["A"].unique()
has_multiple_elements = count_severity.apply(lambda x: len(x)>1)
result = count_severity[has_multiple_elements]
result.to_csv("./output_file.csv", sep=";", line_terminator=None)
In the output file I get the data in the following form:
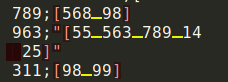
Could you tell me please, how can square brackets [] (highlighted in red) and quotation marks "" (highlighted in red) be removed, and spaces (highlighted in yellow) replaced, for example, with a comma? I assume that the quotes appear as a result of the line break \n, i.e. in the second line between the digits 14 and 25 is \n. I tried using the parameter line_terminator=None but he did not come to success.
CodePudding user response:
If you can use another format except csv, as lists are containers, pickle would be convenient in this case:
result.to_pickle("./output_file.csv")
df2 = pd.read_pickle("./output_file.csv")
CodePudding user response:
So far, nothing comes to mind, except for this solution:
output_file = open("./output_file.csv", "r")
output_file = ''.join([i for i in output_file]).replace("[]", "")
output_file_new = open("./output_file_new.csv", "w")
output_file_new.writelines(output_file)
output_file_new.close()
Well, so a few replaces ...
I am waiting for the evaluation of experts on this solution, please give your comment. Thanks