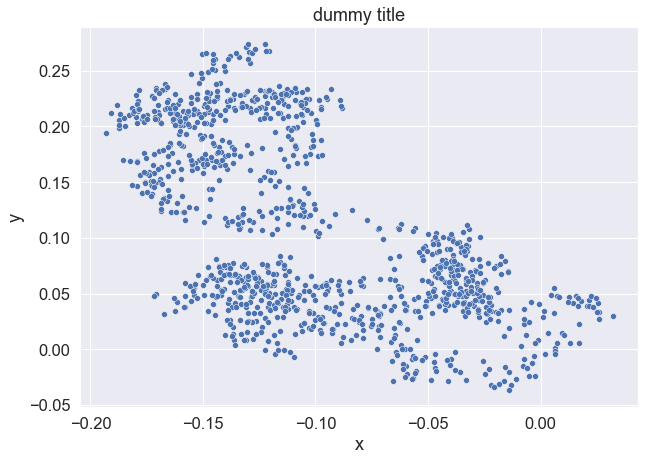
My data is in a dataframe of two columns: y and x. The data refers to the past few years. Dummy data is below:
np.random.seed(167)
rng = pd.date_range('2017-04-03', periods=365*3)
df = pd.DataFrame(
{"y": np.cumsum([np.random.uniform(-0.01, 0.01) for _ in range(365*3)]),
"x": np.cumsum([np.random.uniform(-0.01, 0.01) for _ in range(365*3)])
}, index=rng
)
In first attempt, I plotted a scatterplot with Seaborn using the following code:
import seaborn as sns
import matplotlib.pyplot as plt
def plot_scatter(data, title, figsize):
fig, ax = plt.subplots(figsize=figsize)
ax.set_title(title)
sns.scatterplot(data=data,
x=data['x'],
y=data['y'])
plot_scatter(data=df, title='dummy title', figsize=(10,7))
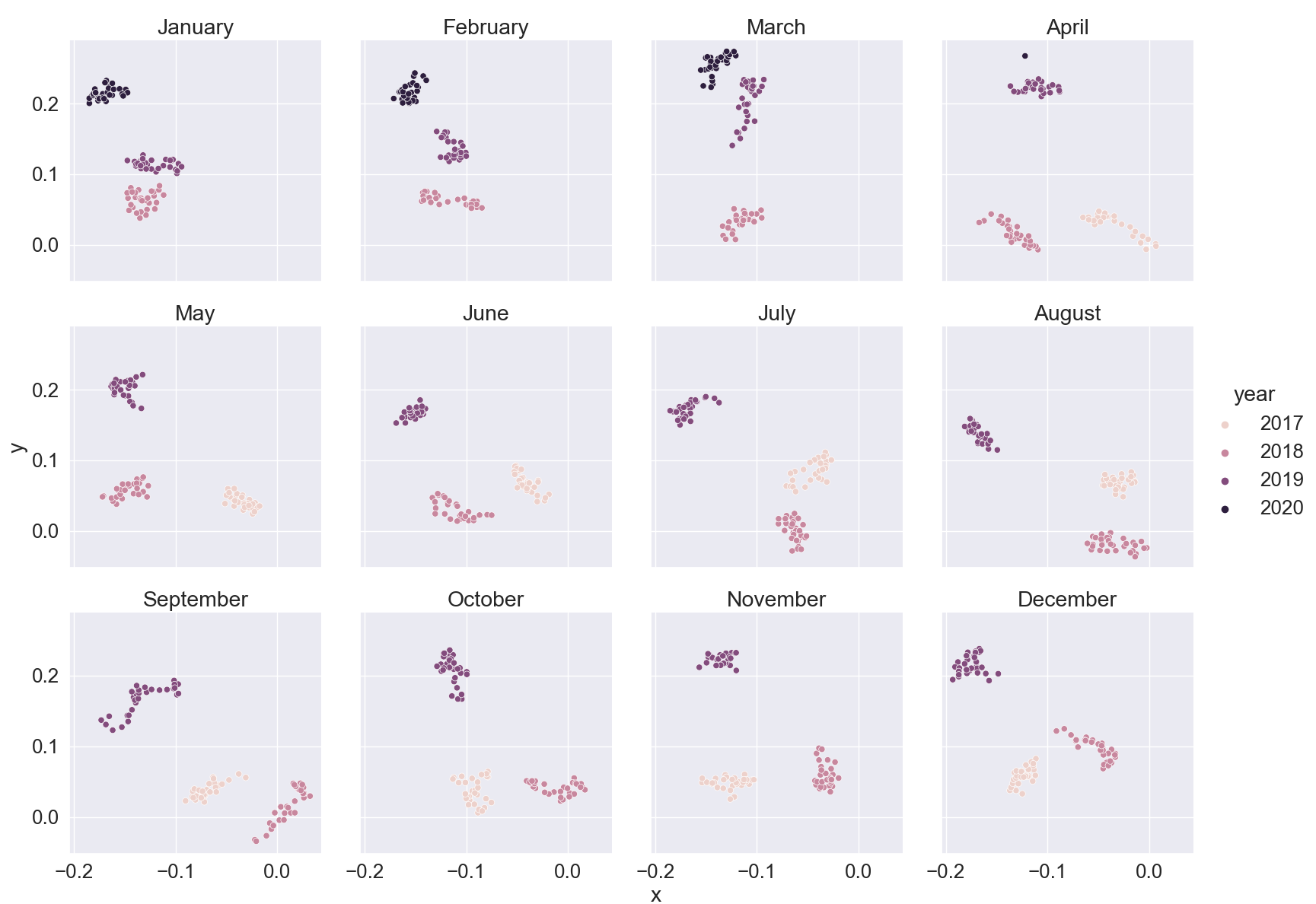
 However, I would like to generate a 4x3 matrix including 12 scatterplots, one for each month with year as hue. I thought I could create a third column in my dataframe that tells me the year and I tried the following:
However, I would like to generate a 4x3 matrix including 12 scatterplots, one for each month with year as hue. I thought I could create a third column in my dataframe that tells me the year and I tried the following:
import seaborn as sns
import matplotlib.pyplot as plt
def plot_scatter(data, title, figsize):
fig, ax = plt.subplots(figsize=figsize)
ax.set_title(title)
sns.scatterplot(data=data,
x=data['x'],
y=data['y'],
hue=data.iloc[:, 2])
df['year'] = df.index.year
plot_scatter(data=df, title='dummy title', figsize=(10,7))
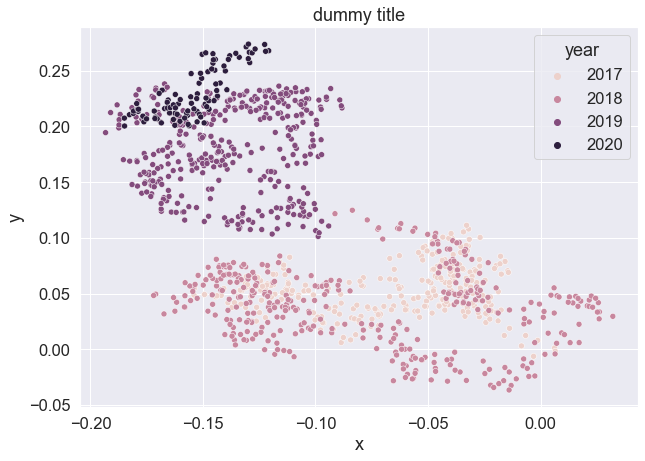 While this allows me to see the years, it still shows all the data in the same scatterplot instead of creating multiple scatterplots, one for each month, so it's not offering the level of detail I need.
While this allows me to see the years, it still shows all the data in the same scatterplot instead of creating multiple scatterplots, one for each month, so it's not offering the level of detail I need.
I could slice the data by month and build a for loop that plots one scatterplot per month but I actually want a matrix where all the scatterplots use similar axis scales. Does anyone know an efficient way to achieve that?
CodePudding user response:
To create multiple subplots at once, seaborn introduces