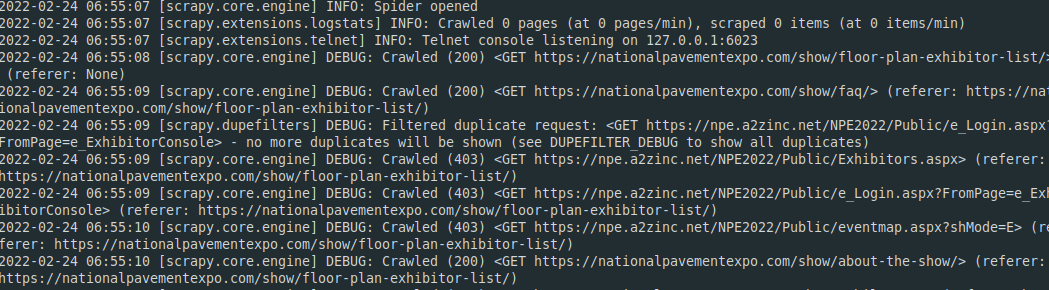
I'm stuck trying to find a way to make my spider work. This is the scenario: I'm trying to find all the URLs of a specific domain that are contained in a particular target website. For this, I've defined a couple of rules so I can crawl the site and find out the links of my interest.
The thing is that it doesn't seem to work, even when I know that there are links with the proper format inside the website.
This is my spider:
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class sp(CrawlSpider):
name = 'sp'
start_urls = ['https://nationalpavementexpo.com/show/floor-plan-exhibitor-list/']
custom_settings = {
'LOG_LEVEL': 'INFO',
'DEPTH_LIMIT': 4
}
rules = (
Rule(LinkExtractor(unique=True, allow_domains='a2zinc.net'), callback='parse_item'),
Rule(LinkExtractor(unique=True, canonicalize=True, allow_domains = 'nationalpavementexpo.com'))
)
def parse_item(self, response):
print(response.request.url)
yield {'link':response.request.url}
So, in summary, I'm trying to find all the links from 'a2zinc.net' contained inside