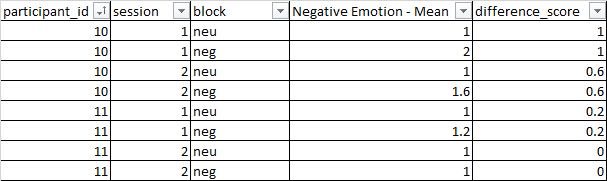
I need to calculate a difference score between 2 cells in the columns 'Negative Emotions - Mean', with the same values in the columns 'participant_id' and 'session'. the difference score is block=neg minus block=neu My expected output is presented in the column 'difference_score'
How can I do it pandas, without building a dictionary?
Thank in advance!
CodePudding user response:
Over simple way would be to set the ID columns as index and using a mask:
df2 = df.set_index(['participant_id', 'session'])
mask = df2['block'].eq('neg')
df2['difference_score'] = df2.loc[mask, 'Negative Emotions - Mean']-df2.loc[~mask, 'Negative Emotions - Mean']
df2.reset_index()
No output provided as the data was an image.
CodePudding user response:
One way to do this is to leverage pandas' pandas.DataFrame.groupby and pandas.DataFrame.groupby.GroupBy.apply functions.
Groupby groups your DataFrame based on the specified columns, then apply runs whatever function you pass through over the GroupBy object.
So, first, let's formulate the logic you'd like to do, first, you want to groupby the participant_id and the session, then you'd like to get the value for the neg, and the value for the neu, and then place this difference into a new column named difference_score.
# This function will get the difference from the grouped rows.
def get_score_difference(rows: pd.DataFrame):
# Get neg value in a try catch block, ensuring neg is defaulted to 0 if not in df
try:
neg = rows.loc[rows['block'] == 'neg']['Negative Emotion - Mean'][0]
except Exception as e:
neg = 0
# Get neu value in the same fashion as neg
try:
neu = rows.loc[rows['block'] == 'neu']['Negative Emotion - Mean'][0]
except Exception as e:
neu = 0
# Add new column with neg - neu
rows['difference_score'] = neg - neu
# Return new rows
return rows
# Apply the function to the dataframe
df.groupby(['participant_id', 'session']).apply(get_score_difference)