DATA <- data.frame("V1" = c("SCORE : 9.931 5.092",
"SCORE : 6.00007 15.1248",
"SCORE : 1.0002 12.987532",
"SCORE : 3.1 3.98532"))
WANT <- data.frame("VAR1" = c(9.931, 6.00007, 1.0002, 3.1),
'VAR2' = c(5.092, 15.1248, 12.987532, 3.98532))
What I have is student test score data that was entered like shown in 'DATA' but I wish to split it so that what I have is like what is shown in the 'WANT' frame where the first number is in 'VAR1' and the second number is in 'VAR2' ignoring the spaces
MY ATTEMPT:
DATA[, c("VAR1", "VAR2") := trimws(V1, whitespace = ".*:\\s ")]
PRODUCE:
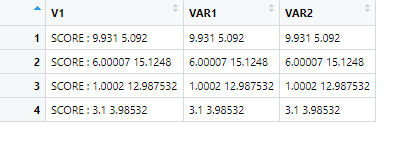
CodePudding user response:
We can remove the prefix substring with trimws and read the column using read.table with sep as default space to return two column data.frame in base R
read.table(text = trimws(DATA$V1, whitespace = ".*:\\s "),
header = FALSE, col.names = c("VAR1", "VAR2"))
VAR1 VAR2
1 9.93100 5.09200
2 6.00007 15.12480
3 1.00020 12.98753
4 3.10000 3.98532
Or may use extract from tidyr
library(tidyr)
extract(DATA, V1, into = c("VAR1", "VAR2"),
".*:\\s ([0-9.] )\\s ([0-9.] )", convert = TRUE)
VAR1 VAR2
1 9.93100 5.09200
2 6.00007 15.12480
3 1.00020 12.98753
4 3.10000 3.98532
If we want data.table, using the same method can read with fread after removing the prefix substring
library(data.table)
fread(text = setDT(DATA)[, trimws(V1, whitespace = ".*:\\s ")],
col.names = c("VAR1", "VAR2"))
VAR1 VAR2
<num> <num>
1: 9.93100 5.09200
2: 6.00007 15.12480
3: 1.00020 12.98753
4: 3.10000 3.98532
Or use the select option in fread
fread(text = DATA$V1, select = c(3, 4), col.names = c("VAR1", "VAR2"))
VAR1 VAR2
<num> <num>
1: 9.93100 5.09200
2: 6.00007 15.12480
3: 1.00020 12.98753
4: 3.10000 3.98532
Or read as four columns, and subset
fread(text = DATA$V1)[, .(VAR1 = V3, VAR2 = V4)]
VAR1 VAR2
<num> <num>
1: 9.93100 5.09200
2: 6.00007 15.12480
3: 1.00020 12.98753
4: 3.10000 3.98532
Or can use tstrsplit
setDT(DATA)[, c("VAR1", "VAR2") := tstrsplit(trimws(V1,
whitespace = ".*:\\s "), " ")]
DATA <- type.convert(DATA, as.is = TRUE)
DATA
V1 VAR1 VAR2
<char> <num> <num>
1: SCORE : 9.931 5.092 9.93100 5.09200
2: SCORE : 6.00007 15.1248 6.00007 15.12480
3: SCORE : 1.0002 12.987532 1.00020 12.98753
4: SCORE : 3.1 3.98532 3.10000 3.98532